ML-Agents を使ったゲームをリリースしようと、ここ知らばくUnityばかりしていましたが、ようやくリリースすることができました。 Google Play のこちらからダウンロードできます。 以下、苦労した点の覚書です。まだ、Unityに慣れていないこともあり、もっとよい対 […]
このブログを読んでくれている皆さんもそうだと思いますが、僕はこれまでにいろいろなダイエットに挑戦し、ことごとく失敗してきました。 たまにうまく目標体重まで減らせることもあったのですが、そのあとで、かならずリバウンドしてしまっていました。 年齢が上がるとどんどん痩せにくくなり、最近 […]
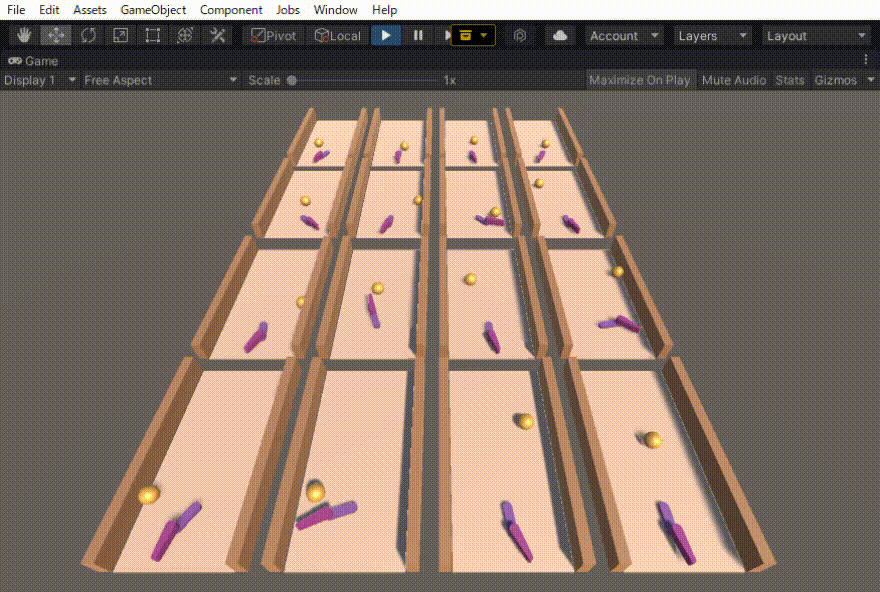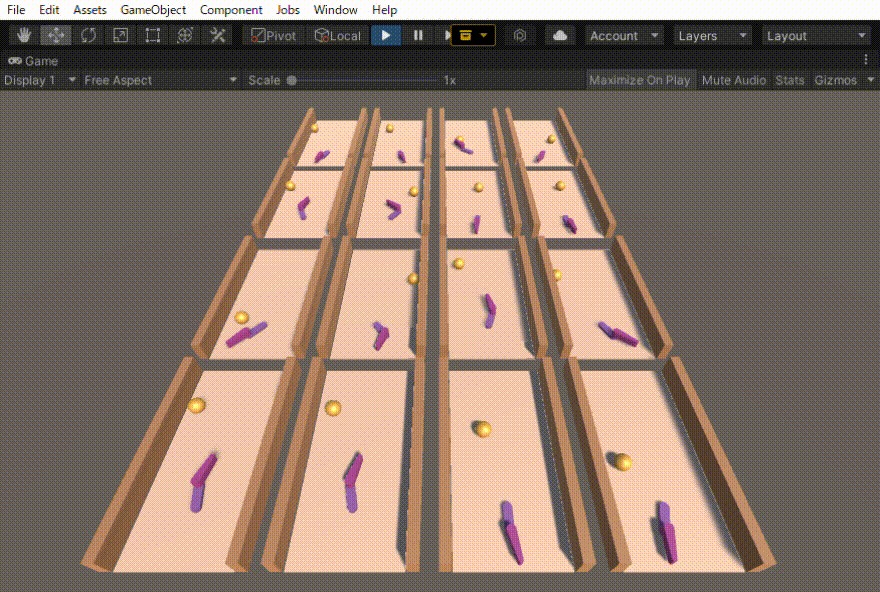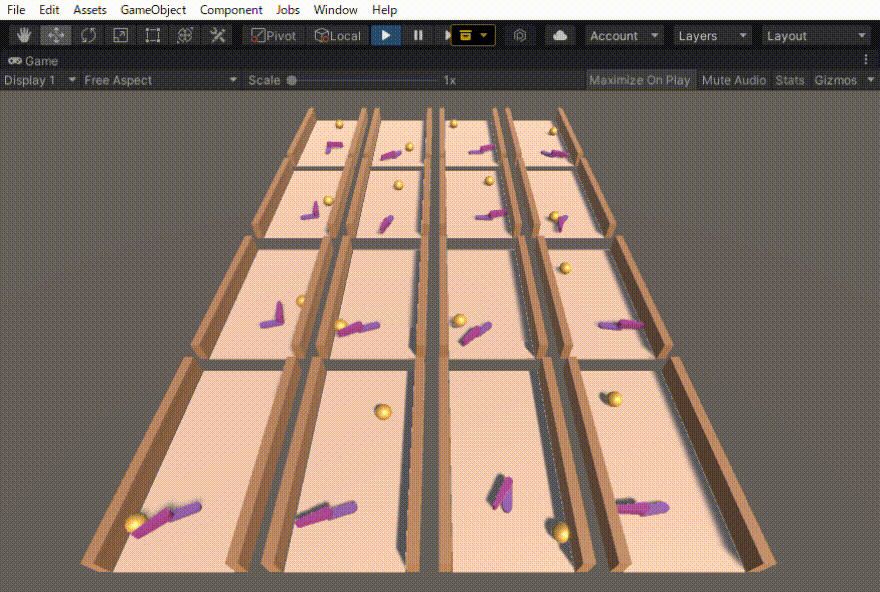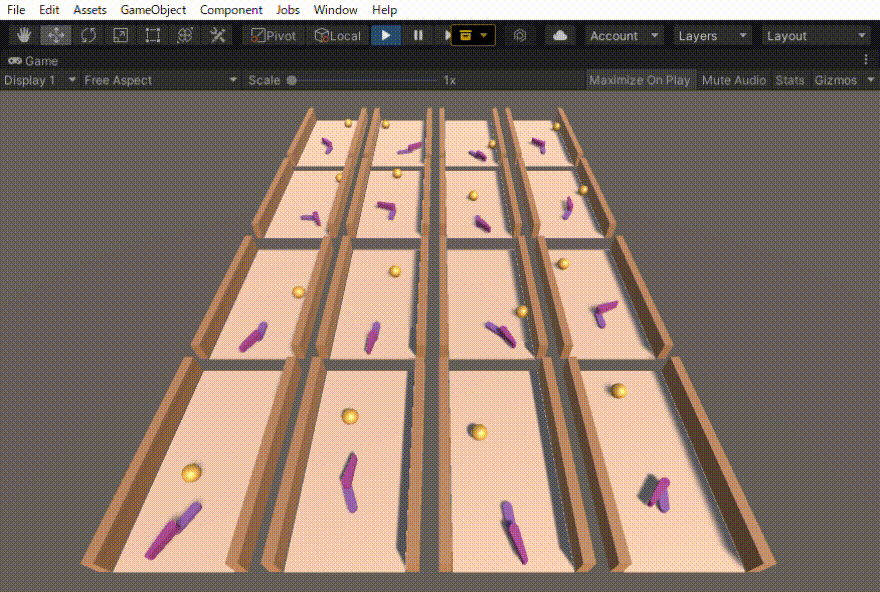
ハンドロンという過去に制作したロボットの動きを強化学習で作りました。その忘備録になります。 ハンドロンとは ハンドロンは、昔作った卓球ボールを打ち返すロボットです。 この時は、ボールを打つ動作はプログラムで作成しておき、その打つ動作を発動させるタイミングを強化学習で調節させました […]
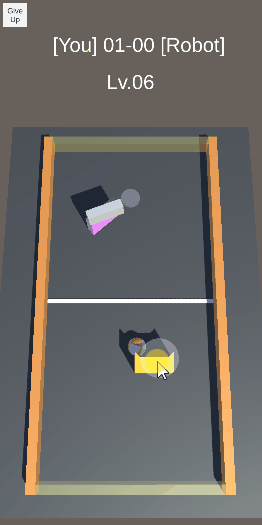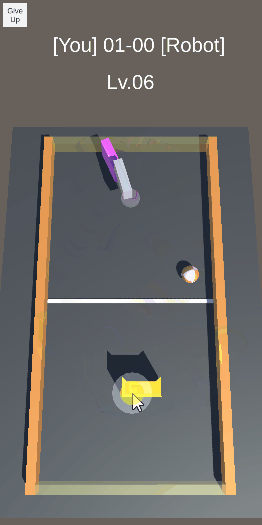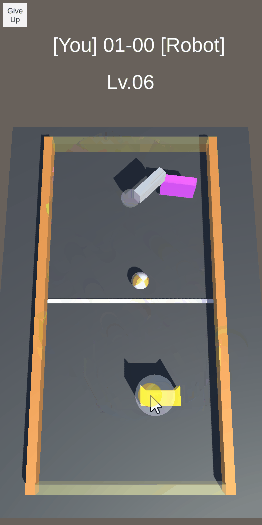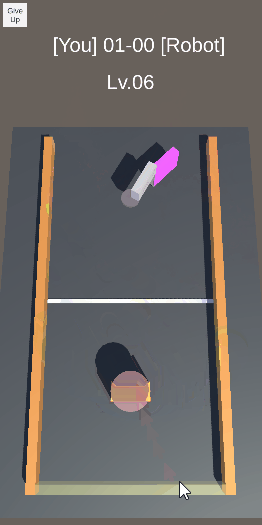
エアホッケーを目指したロボットの実験のの忘備録です。 —– ボールを向こう側に押し出す動作を学習させた。 報酬は、赤いディスクが落ちた時の縦方向の速度(向こう側が正)とした。結構激しい動きだが、ディスクは向こう側に押し出されている。 前回は、稼働部分をHi […]
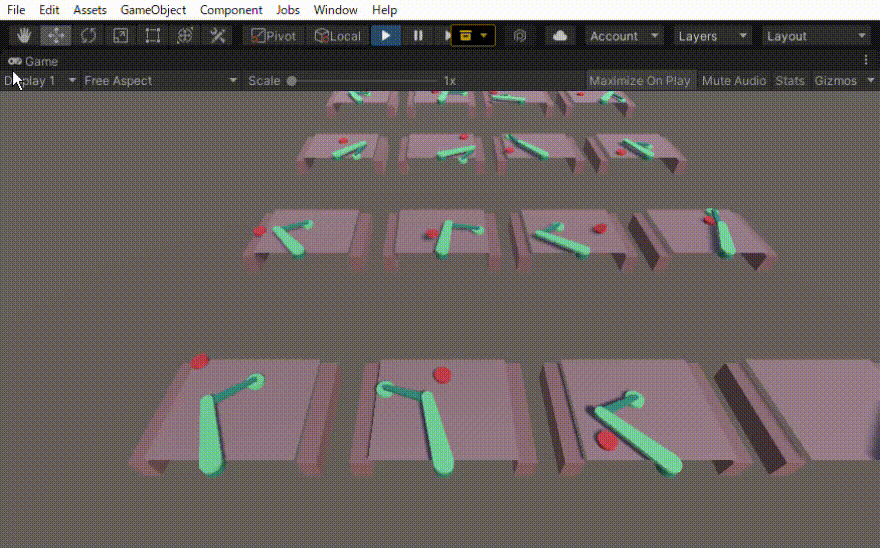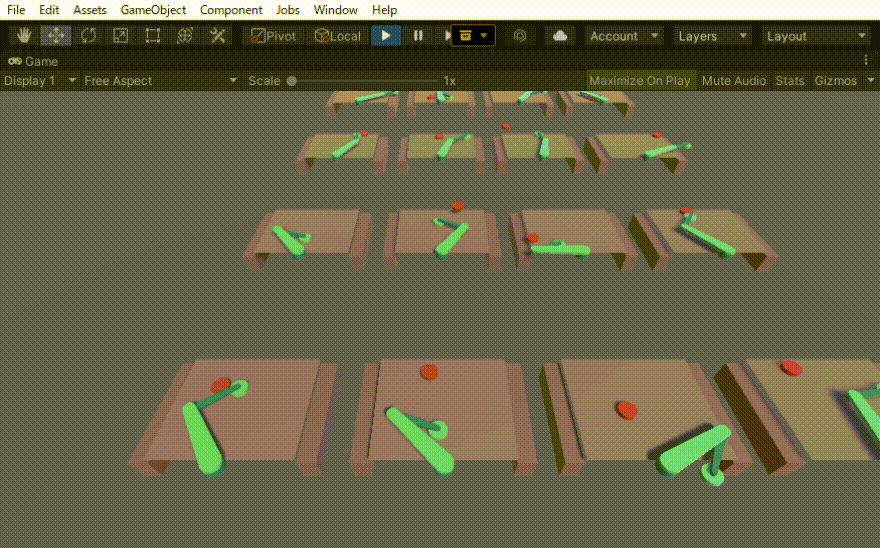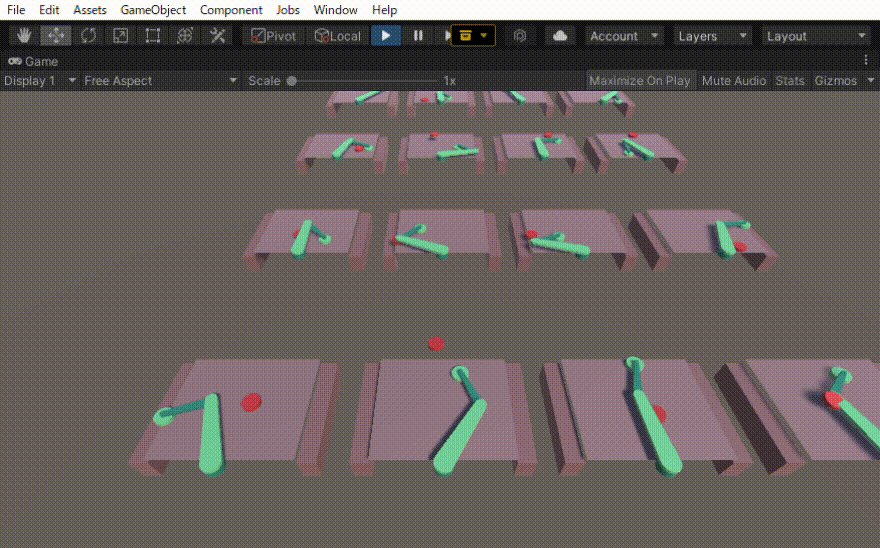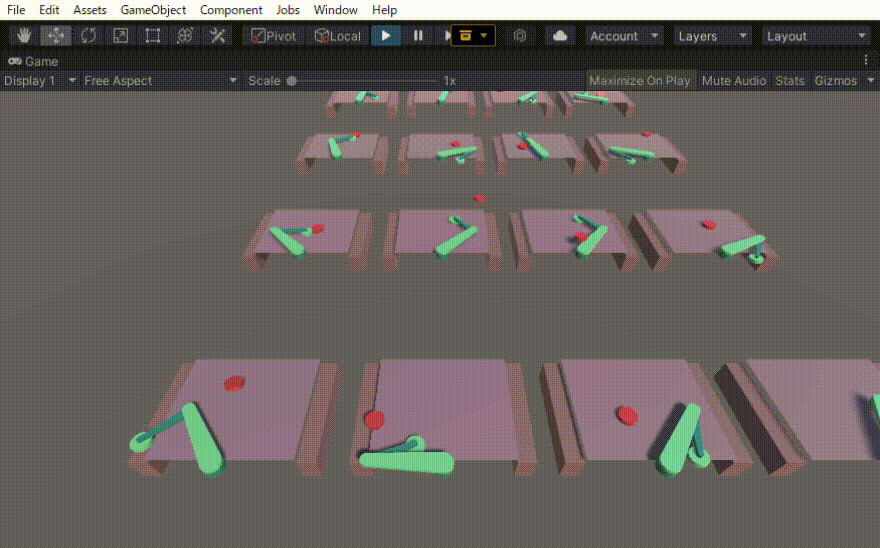
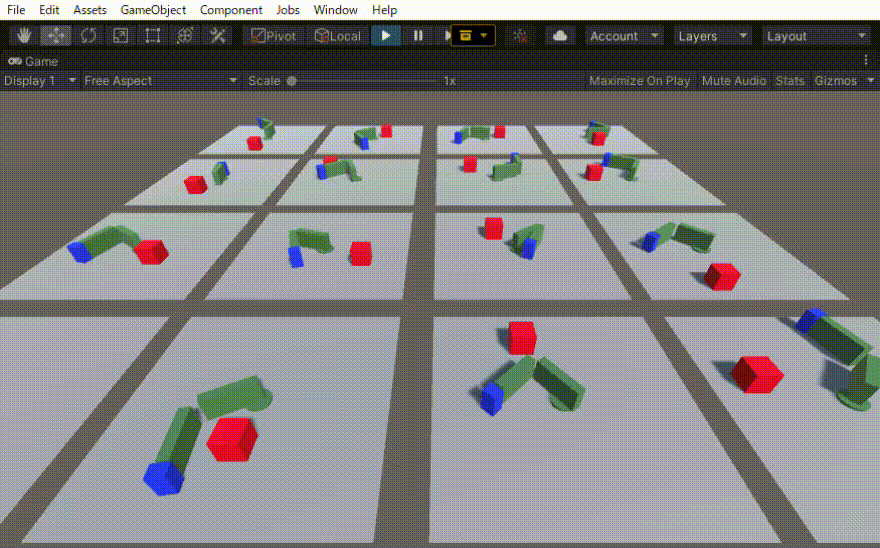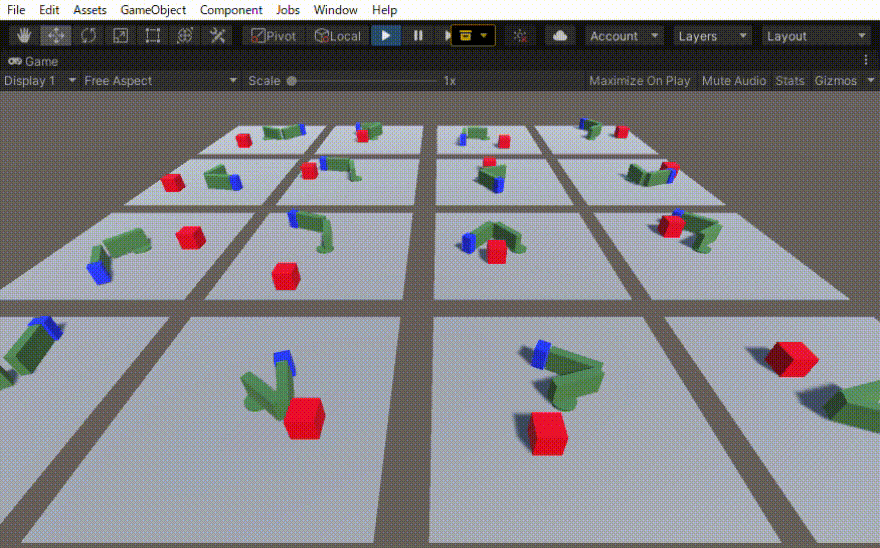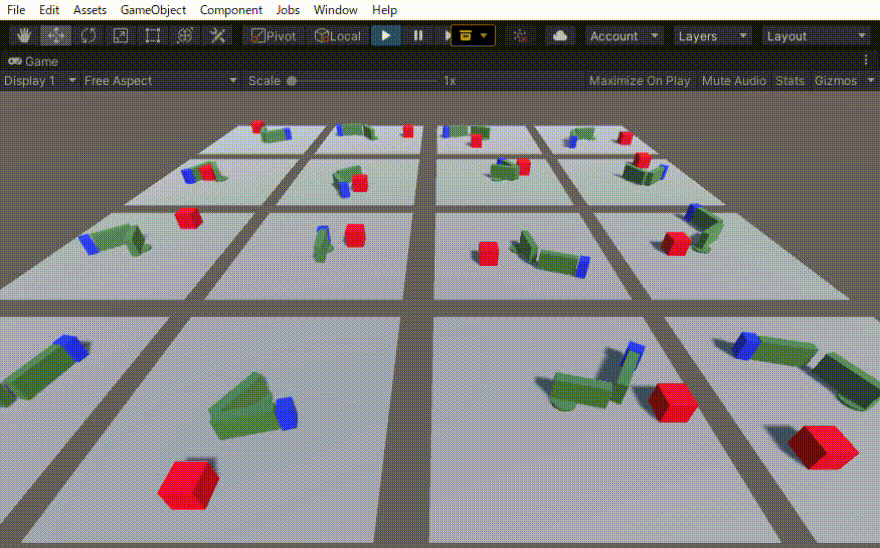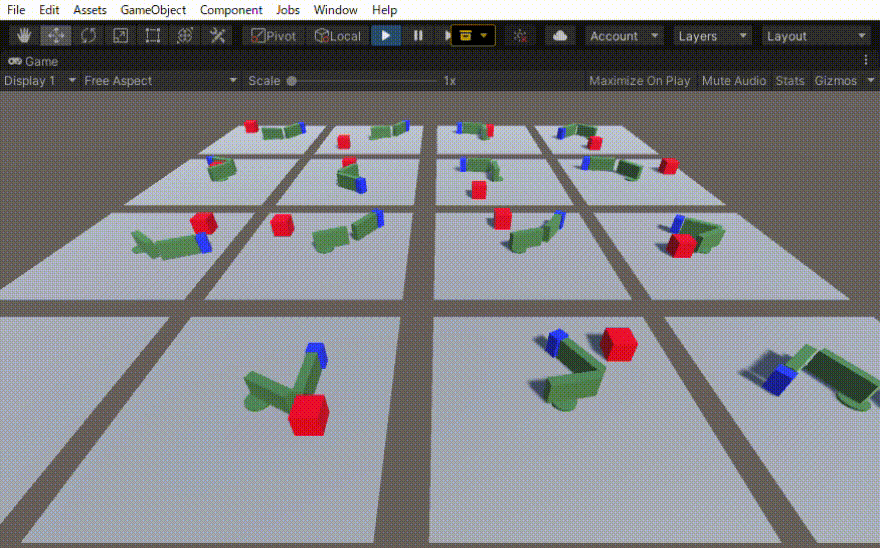
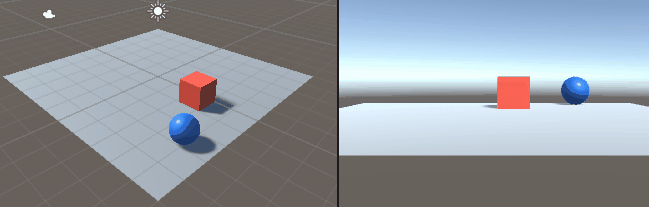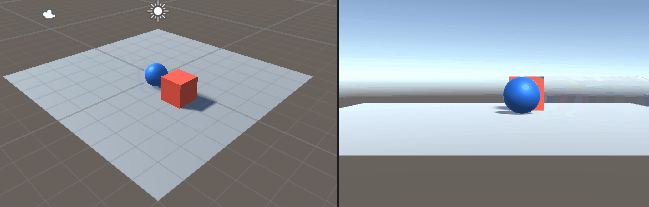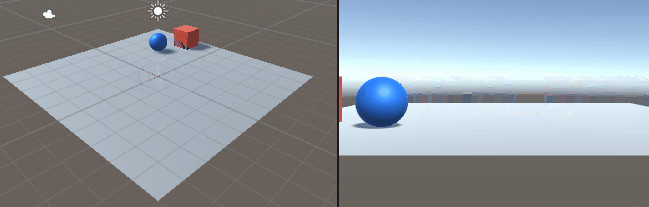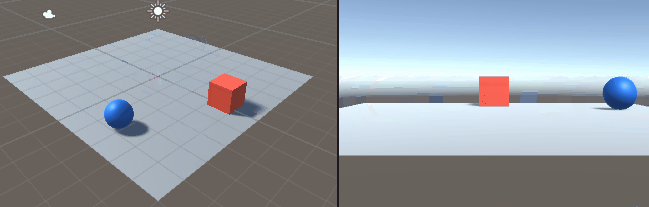
二つのリンクをつなげたハンドのリーチングを学習させました。 この時の設定やプログラムの忘備録です。 以下、作成したゲームオブジェクトです。 リーてぃんぐのTargetはシンプルです。cube を作っただけで、Rigid Bodyは作っていません。Box Collidorはついてい […]
Unity ML-Agents とは、Unityで強化学習をできるようにするUnityのプラグインです。強化学習の「環境」をUnityで動かし、「エージェント」はPython側で動かし、両者を通信させながらエージェントを学習させることができます。 ML-Agents のExamp […]
強化学習の本を書きました。2021/11/20に発売される予定です。 (Amazon 予約はこちらから) 【目次】は以下のようになります。 1章 強化学習の位置づけ 2章 Pythonの環境構築 3章 教師あり学習 4章 強化学習の問題設定 5章 基本のQ学習 […]
q, qnet, gru, lstm のコーディングに間違いはないのでしょうか?その確認をするためには、Q値が正しい値に収束するかをチェックすることが大切です。 また、短期記憶ユニット(gru/lstm)の短期記憶の能力はどれくらいなのでしょうか。定量的に知りたいです。 このよう […]
LSTM/GRUを使ったエージェント、agt_lstm, agt_gru の解説です。 LSTMを取り入れたネットワーク構造 それではqnet にどのようにLSTMを組み込むのが良いのでしょうか。 先行研究として、DQNのネットワークの出力層の手前の全結合層をLSTMに置き換えた […]
短期記憶を取り入れた強化学習を説明します。ここからは、一般的な強化学習の話以外に、筆者独自の考えも書いていきます。 なぜ短期記憶が必要なのか 心理学では、記憶を感覚記憶、短期記憶、長期記憶に分類します。短期記憶とは、数十秒程度しか保持できない記憶とも言われていますが、ここでは、最 […]