短期記憶を取り入れた強化学習を説明します。ここからは、一般的な強化学習の話以外に、筆者独自の考えも書いていきます。
なぜ短期記憶が必要なのか
心理学では、記憶を感覚記憶、短期記憶、長期記憶に分類します。短期記憶とは、数十秒程度しか保持できない記憶とも言われていますが、ここでは、最長1日くらい保持される記憶として、短期記憶と呼ぶことにします。
PCで例えるなら、電源を切ると消えてしまうメモリー(RAM)のイメージです。
私たちは、この短期記憶を頻繁に使っています。例えば、探し物をするときには、なんども同じ箇所を探さないようにします。それができるのは、短期記憶にすでに探した場所が入っているからです。
また、掃除をするときにも同じです。なんども同じ場所ばかり掃除しないのは、短期記憶に掃除した場所が入っているからです。
しかし、普通の強化学習アルゴリズムはこのような記憶の機能がありません。話を掘り下げるために、次のようなタスクを考えます。フタ付きバケツの中の魚を集めるタスクです。できるだけ多くの魚を集めることが目的です。
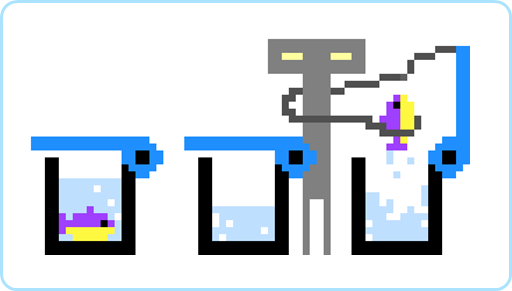
強化学習アルゴリズムがロボットを操作して、バケツのフタを開けて魚を取ったとします。すると、バケツのフタは自動的に閉まります(このような設定になっていると考えてください)。そして、ロボットが観察するモニター画像は、魚を取る前と変わらなくなります。

すると、強化学習は、もう魚がいないのにも関わらず、再び同じフタを開けようとするでしょう。強化学習は、同じ観察に対してはいつも同じ行動しかとれないからです。
しかし、ロボットに短期記憶の機能が備わっていたらどうでしょうか。
「魚を取った」ことを記憶することができ、その情報を行動選択に使うことができれば、魚をとった後は、そのバケツを再び開けることはなく、別なバケツに向かうという行動が学習できるかもしれません。
「かもしれません」と書いたのは、短期記憶があったとしたも、まだ難しい問題が潜んでいて、すぐにこのようなタスクができるわけではないからです。しかし、少なくとも、短期記憶の機能は必須だと考えることができるでしょう。
記憶ユニット
ニューラルネットワークの世界では、短期記憶を使う方法は、時系列情報を学習させる仕組みとして発展してきました。
例えば、以下のような問題です。
入力[math]\bf{x}(t)[/math]と[math]\bf{y}(t)[/math]のペアとなるデータがあります。[math]t[/math]は時間を表しており、データは[math]t=0[/math]から順番に提示されます。目的は、時刻[math]t[/math]において、過去に受け取った入力情報全て[math]\bf{x}(0) \cdots \bf{x}(t) [/math]から[math]\bf{y}(t)[/math]を予測することです。
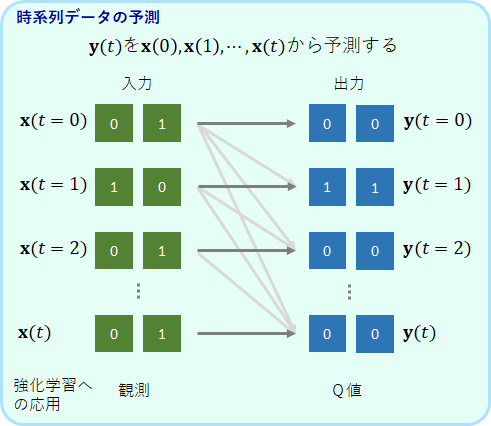
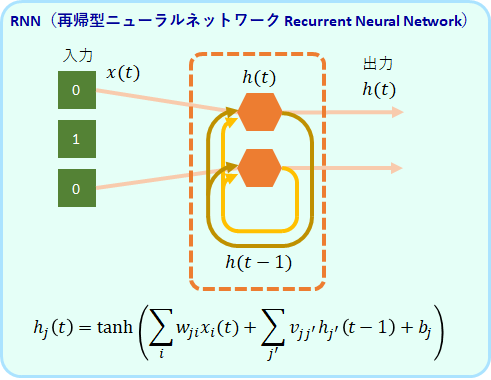
このような問題に対して、RNN(再帰型ニューラルネットワーク Recurrent Neural Network)という仕組みが考えられてきました。
RNNは、以下のようなベクトル表記の方がすっきりして理解しやすいです。
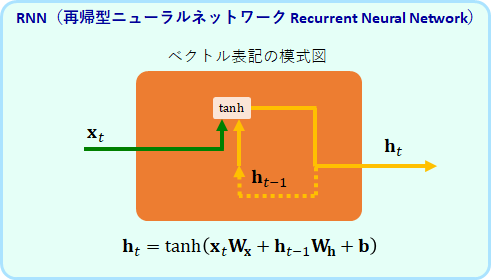
このRNNの層のユニット[math]\bf{h}_t[/math]は、入力[math]\bf{x}_t[/math] だけでなく、自分自身の層の1ステップ前の出力[math]\bf{h}_{t-1}[/math]も入力として受けとります。
この[math]\bf{h}_{t-1}[/math]は、前のステップで、[math]\bf{x}_{t-1}[/math]と[math] \bf{h}_{t-2}[/math]を使って作られたものです。
更に、[math]\bf{h}_{t-2}[/math]は、2ステップ過去の[math]\bf{x}_{t-2}[/math]、[math]\bf{h}_{t-3}[/math]から計算されたものです。
このようにして、初めのステップにまでさかのぼって考えることができますので、[math]\bf{h}_t[/math]は初めから今までの入力全て[math]\bf{x}_0, \bf{x}_1, \cdots, \bf{x}_t[/math]の影響を受けて決まった値ということが分かります。
この[math]\bf{h}[/math]は、過去の入力の集約を保持しているメモリーと考えることもできます。この変数を業界用語では隠れ状態と呼びますが、この記事では、内部状態、または、単にメモリーと呼ぶことにします。
このRNNに、バックプロパゲーションを適用することで、初めに例として出した時系列データを記憶させることができます。しかし完ぺきではなく、ある程度可能ということです。
といいますのも、長い依存関係のある時系列は難しく、学習が不安定(勾配消失、勾配爆発)になるという欠点があるのです。
その欠点を克服するために考案されたのがLSTM (Long short-term memory)です。
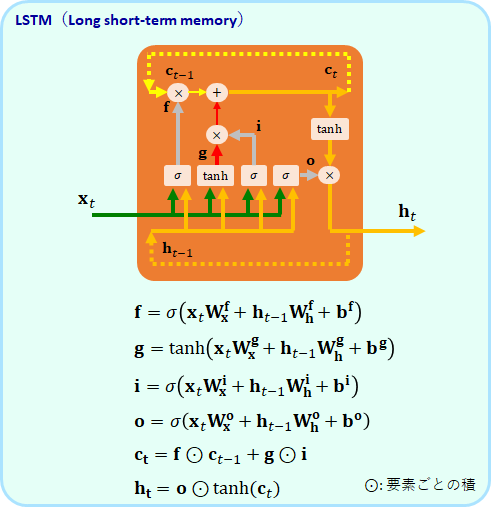
RNNに比べるとかなり複雑で回路のような構造を持っています。ポイントは、[math]\bf{c}_t[/math]という記憶装置が、[math]\bf{h}_t[/math]とは別に組み込まれているところです。
ベクトルである[math]\bf{c}_t[/math]は、特定の入力[math]\bf{x}[/math]に対して、そのパターンを変化させることができます。そして、そのパターンを、特定の入力[math]\bf{x}[/math]に対して、出力[math]\bf{h}[/math]に反映させることができるのです。
モデルの式には8個の[math]\bf{w}[/math]と4つの[math]\bf{b}[/math]があります。これがLSTMのパラメータです。これらは全てバックプロパゲーションで学習させるのですが、LSTMはTensorflowで使用可能ですので、学習のアルゴリズムを自ら書く必要はありません。
ここではこれ以上、LSTMのメカニズムについて踏み込みませんが、更に詳しく知りたいという方は、以下の本が参考になります。


このLSTMを使うと、時系列データを学習させることができます。具体的な例は、LSTMをKerasで動かす パルス波の予測にまとめましたので、興味がある方は参考にしてください。
それにしても、このモデルを眺めると、強化学習の短期記憶にうってつけのように思えてきます。例えば、観測を入力とした場合、以下ようなことが可能なのではないでしょうか。
例えば、ある覚えるべき特定のパターンが観察されたら(前の例では、魚を取ったという観察)、[math]\bf{c}[/math]の特定の要素を1にします。この1はずっと保持させることができます。そして、次の特定の観察パターンが入力されたとき(バケツのフタの観察)、その記憶していた1があることで、出力を変化させるのです(フタを開けるという行動のQ値を下げる)。
しかし、LSTMの回路は少し冗長的な気もします。例えば、fは忘却ゲートでiは入力ゲートを意味しますが、独立に変えるできます。しかし、f + i = 1 のような制限があってもよさそうです。
そのような意味合いだと思うのですが、LSTMを単純化したGRU(Gated recurrent unit)というモデルが提案されています。これもTensorflow で使うことができます。
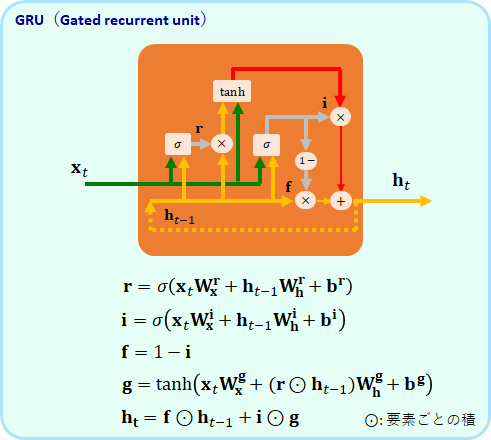
GRUでは、fの忘却ゲートとiの入力ゲートが足して1になる制限が入っています。そして、LSTMに合った[math]\bf{c}[/math]が廃止され、メモリーは[math]\bf{h}[/math]だけとなっています。モデルのパラメータとして、6個の[math]\bf{w}[/math]と3つの[math]\bf{b}[/math]がありますが、LSTMよりも少なくなっていることが分かります。
GRUの詳細については以下の本が参考になります。
余計なパラメータを削減した(と著者は思っている)GRUの方が、LSTMよりも学習が速いのではと期待があったので、memoryRLでは、LSTMだけでなくGRUのでもエージェントを作りました。