LSTM/GRUを使ったエージェント、agt_lstm, agt_gru の解説です。
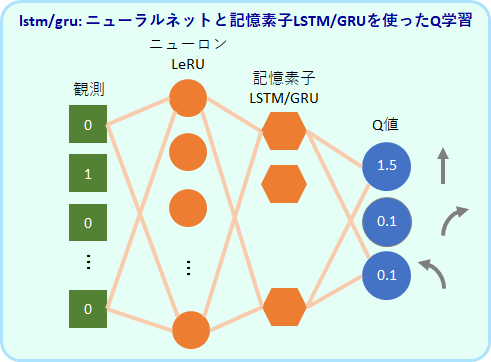
LSTMを取り入れたネットワーク構造
それではqnet にどのようにLSTMを組み込むのが良いのでしょうか。
先行研究として、DQNのネットワークの出力層の手前の全結合層をLSTMに置き換えただけというモデル、DRQN (Deep Recurrent Q-Network)が提案されています(Hausknecht 2017)。
この論文では、Pong というボールを打ち合うゲームをDRQNに学習させ、画面を時々見えなくしてもそこそこプレイできることを示しています。
DRQNの論文での例題は、筆者が考える短期記憶を意識した実装ではないように思いますが、ここでのLSTMの使い方に習って、出力層の手前にLSTMを入れたニューラルネット agt_lstm.py と、代わりに GRU を入れたagt_gru.py を作りました。
両者のプログラムは、ほとんど同じですので、以下、agt_lstm.py を説明していきます。
リプレイメモリー
agt_lstm.py では、タスクを実行するフェイズと学習するフェイズを別々に交互に行います。
タスクを実行するフェイズでは、毎ステップ、前の観察x, 前の行動a, 報酬 r, 今の観察x を経験 e というセットにして、経験記憶クラス(ReplayMemory)に保存します。これは、前章で述べてきた短期記憶とは別物です。
学習するフェイズでは、経験記憶クラスのデータを使って、ネットワークのトレーニングをします。
トレーニングでは、この二つのフェイズを繰り返し行っていきます。なぜ、このようにフェイズを分けたかというと、LSTMの内部状態が、実行時の処理でも学習時の処理でも変化してしまい、同時に行うと互いに干渉してしまうからです。
DQNでもこのようなリプレイメモリーが使われていますが、若干の違いがあります。DQNではメモリーのサンプリングはランダムに行います。一方、ここでのリプレイメモリーは、時系列学習をさせることが目的なので、保存されているエピソードをランダムに選んだら、そのままの順番でまとまった経験をサンプリングするようにしています。

class ReplayMemory の具体的なコードです。
"""
replaymemory.py
経験の記憶モジュール
"""
import random
import numpy as np
class ReplayMemory():
"""
経験を記録する
"""
def __init__(self, memory_size):
self.memory_size= memory_size
self.index = 0
self.memory = []
self.sub_memory = []
def add(self, experience, done):
"""
経験を記憶に追加する
"""
self.sub_memory.append(experience)
if done is True:
self.memory.append(self.sub_memory)
if len(self.memory) > self.memory_size:
self.memory.pop(0)
self.sub_memory = []
def sample(self, data_length):
"""
batchs は常にスタート地点から始まる
"""
mem_size = len(self.memory)
if mem_size == 0:
return None
idx = random.sample(range(mem_size), mem_size)
cnt = 0
batchs = []
while True:
batchs = batchs + self.memory[idx[cnt]]
if len(batchs) >= data_length:
break
cnt = (cnt + 1) % mem_size
batchs = batchs[:data_length]
out = []
for i in range(len(batchs[0])):
out.append(np.array([bb[i] for bb in batchs]))
return out
add(experience)で経験を追加し、sample(data_length)で、data_length分の経験を取り出します。memory_size は、蓄えるエピソードの数です。
パラメータ設定、__init__()
それでは、agt_lstm.py の中身の説明に入ります。
__init_()では、パラメータのセッティングをします。実際に使用するパラメータの値は、sim_swamptour.py に記述されていますので、ここではどんなものがあるかを見ていきます。
qnet から新しく入ったパラメータは、まず、n_lstm です。これはLSTMユニットの数です。
memory_sizeはReplayMemoryで保存するエピソード数、data_length_for_learnは、取り出す経験の数です。
実行と学習は交互に行うという説明をしましたが、learn_interval は、何ステップの実行毎に学習を行うかを決めるパラメータです。
epochs_for_train, batch_sizse, data_length は、学習時のデータのパラメータですが、今のところ全て1で使います。
import sys
import numpy as np
import tensorflow as tf
import replaymemory as mem
import core
class Agt(core.coreAgt):
"""
出力層の手前にLSTMを配置したエージェント
"""
def __init__(
self,
n_action=2,
input_size=(7, ),
epsilon=0.1,
gamma=0.9,
n_dense=32,
n_dense2=None,
n_lstm=8,
memory_size=20,
data_length_for_learn=20,
learn_interval=10,
epochs_for_train=1,
batch_size=1,
data_length=1,
filepath=None,
):
"""
Parameters
----------
n_action: int
行動の種類の数
input_size: tuple of int 例 (7,), (5, 5)
入力の次元
epsilon: float (0から1まで)
Q学習のε、乱雑度
gammma: float (0から1まで)
Q学習のγ、割引率
n_dense: int
中間層1のニューロン数
n_dense2: int or None
中間層2のニューロン数
None の場合は中間層2はなし
n_lstm: int
lstm層のユニット数
memory_size: int
メモリーに蓄えるエピソード数
learn_interval: int
何ステップ毎に学習するか
data_length_for_learn: int
1回の学習時につかう連続データの長さ
epochs_for_train: int
1回の学習のエポック数(1でよい)
batch_size: int (1にすること)
バッチサイズ 今は1のみで対応
data_length: int (1にすること)
一度にモデルに入れるエピソード数 今は1のみで対応
filepath: str
セーブ用のファイル名
"""
# パラメータ
self.n_action = n_action
self.input_size = input_size
self.epsilon = epsilon
self.gamma = gamma
self.n_dense = n_dense
self.n_dense2 = n_dense2
self.n_lstm = n_lstm # (B)
self.memory_size = memory_size
self.learn_interval = learn_interval
self.data_length_for_learn = data_length_for_learn
self.epochs_for_train = epochs_for_train
self.batch_size = batch_size
self.data_length = data_length
self.filepath = filepath
super().__init__()
# 変数
self.time = 0
モデル生成、build_model()
モデルの生成は、build_model()で行います。実質的なモデルの生成は、_build_model()で行っています。
LSTMを使っているために、(A)のTimeDistributed のラッパーを使用しています。バッチは1、時系列データの長さも1として(1batch_size=1, data_length=1)、1つの観察情報を1回ずつ入れていく想定です。
(B) で LSTMを定義しています。LSTMの内部状態 state_h, state_c も (C) の output に含めて参照できるようにしています(gruの場合には、内部状態は一つになります)。
class Agt(core.coreAgt):
-- 省略
def build_model(self):
# memory instanse生成
self.replay_memory = mem.ReplayMemory(
memory_size=self.memory_size,
)
# modelのinstanse生成
self.model = self._build_model()
self.model.compile(
optimizer='adam',
loss={'dense_out': 'mean_squared_error'},
metrics=['mse']
)
self.lstm = self.model.get_layer('lstm')
def _build_model(self):
inputs = tf.keras.Input(
batch_shape=((self.batch_size, self.data_length) + self.input_size),
name='input',
)
# (batch_size, data_length, input_size[0], input_size[1])
# batch_size = 1, data_length = 1
x = tf.keras.layers.TimeDistributed( # (A)
tf.keras.layers.Flatten(),
)(inputs)
# (batch_size, data_length, input_size[0] * input_size[1])
x = tf.keras.layers.TimeDistributed( # (A)
tf.keras.layers.Dense(self.n_dense, activation='relu'),
name='dense',
)(x)
# (batch_size, data_size, n_dense)
if self.n_dense2 is not None:
x = tf.keras.layers.TimeDistributed( # (A)
tf.keras.layers.Dense(self.n_dense2, activation='relu'),
name='dense2',
)(x)
# (batch_size, data_size, n_dense2)
x, state_h, state_c = tf.keras.layers.LSTM( # (B)
self.n_lstm,
return_state=True, # 内部状態を出力
return_sequences=True, # 逐次出力
stateful=True, # バッチ間の状態維持
name='lstm',
)(x)
# (batch_size, data_length, n_lstm)
# state_c = (1, n_lstm)
# state_h = (1, n_lstm)
outputs = tf.keras.layers.Dense(
self.n_action,
activation='linear',
name='dense_out',
)(x)
# (batch_size, data_length, n_action)
model = tf.keras.Model(
inputs=inputs,
outputs=[outputs, state_h, state_c] # (C)
)
return model
行動選択、select_action()
行動選択は、qnet の時と同じepsilon-greedy法です。(A)でQ値を得て、(B)で最もQ値が大きい行動を出力します。そして、(C) epsilon の確率でランダム出力をします。
ただし、(A)の get_Q()の内部について少しコメントがあります。
この関数の中の(D)で、model.predict()を実行してQを得ていますが、このmodel.predict()を1回実行すると内部状態が変化しますので、同じ入力に対しても2回目を実行すると出力は異なってきます。
また、(D)の model.predict()のoutput は、build_model()で指定したように、LSTMの内部状態 hstate0, hstate1 も出力されます。gru の場合は、内部状態が1つなのでhstate のみとなっています。
class Agt(core.coreAgt):
-- 省略
def select_action(self, observation):
Q = self.get_Q(observation) # (A)
if self.epsilon < np.random.rand():
action = np.argmax(Q) # (B)
else:
action = np.random.randint(0, self.n_action) # (C)
return action
def get_Q(self, observation):
obs = self._trans_code(observation)
try:
Q, hstate0, hstate1 = \
self.model.predict(obs.reshape((1, 1) + self.input_size)) # (D)
self.state0 = hstate0
self.state1 = hstate1
except:
print('obs のサイズが間違っています。')
sys.exit()
Q = Q.reshape(-1)
return Q
def _trans_code(self, observation):
return observation
Q学習、learn()
学習の部分です。このlearn()は、Class Trainer の中で毎ステップ実行されますが、毎回行われるのは経験の登録のみで、実際に学習が行われるのは、learn_interval で指定したstep 毎になります(A)。
学習に入る場合には、気を付けないといけないことがあります。それは、学習をすると、今までの内部状態が壊れてしまうということです。そこで、学習に入る前には、いったん(B)で内部状態を保存し、学習が終わったら(D)でもとの内部状態に戻します。
実際の学習は(C)で実行している _fit() (E)で行っています。学習のプロセスでも内部状態の扱いに注意が必要です。
まず、ターゲットデータを作ります。
はじめに、内部状態をリセットします(F)。学習をさせていない実行時では、エピソードの開始時に内部状態をリセットしているので、それと同じ状態にするという意味があります。
(G)で、data_length_for_learnの長さの観測 observationを model.predict() に順番に入力し、Qss にQ値をまとめます。このとき、エピソードが終了していたら(done==True) 内部状態をリセットするようにします。次のエピソード開始時のためです。
(H)で、Qssを使ってTarget を作成し、Tssにまとめます。同時に、観測データXss もまとめます。
(I)でモデルの内部状態をリセットしたあと、(J)で実際に学習を行います。データーXssとTssから1ステップ分ずつ取り出してmodel.fit()で学習させます。これをデータ分繰り返します。これも、エピソードが終了していたらその都度内部状態をリセットするようにします。
通常の教師あり学習では、データをまとめてmodel.fit()にセットし、一気に学習させることができるのですが、強化学習の場合は、特に、時系列データとして扱わなくてはならないLSTMの場合は、かなり面倒になりますね。
class Agt(core.coreAgt):
-- 省略
def learn(self, observation, action, reward, next_observation, done):
"""
Q(obs, act)
<- (1-alpha) Q(obs, act)
+ alpha ( rwd + gammma * max_a Q(next_obs))
input : (obs, act)
output: Q(obs, act)
target: rwd + gamma * max_a Q(next_obs, a)
"""
self.replay_memory.add((observation, action, reward, next_observation, done), done)
if self.time % self.learn_interval ==0 and self.time > 0: # (A)
self.save_state() # (B)
self._fit() # (C)
self.load_state() # (D)
self.time += 1
def _fit(self): # (E)
sum_mem = sum([len(mm) for mm in self.replay_memory.memory])
if sum_mem < self.data_length_for_learn:
return
self.reset() # (F)
outs = self.replay_memory.sample(data_length=self.data_length_for_learn)
obss, acts, rwds, _, dones = outs
Xss = []
Tss = []
# 学習データ作成
Qss = []
self.reset()
for i in range(self.data_length_for_learn): # (G)
obs = self._trans_code(obss[i])
obs = obs.reshape((1, 1) + (self.input_size))
Qss.append(self.model.predict(obs)[0][0][0])
if bool(dones[i]) is True:
self.reset()
for i in range(self.data_length_for_learn - 1): # (H)
Qs = Qss[i]
next_Qs = Qss[i + 1]
iact = np.argmax(next_Qs)
if bool(dones[i]) is False:
target = rwds[i] + self.gamma * next_Qs[iact]
else:
target = rwds[i]
Qs[acts[i]] = target
obs = self._trans_code(obss[i])
Xss.append(obs.reshape((1, 1) + (self.input_size)))
Tss.append(Qs.reshape(1, 1, -1))
# 学習
self.reset() # (I)
for i in range(self.data_length_for_learn - 1): # (J)
# Qs
self.model.fit(
{'input': Xss[i]},
{'dense_out': Tss[i]},
batch_size=1,
verbose=0,
epochs=self.epochs_for_train,
shuffle=False,
)
if dones[i] is True:
self.reset()
内部状態のリセット・保存・ロード、reset(), save_state(), load_state()
内部状態のリセット・保存・ロードは、学習の前後や学習のプロセスで使われていました。その具体的なコードです。
class Agt(core.coreAgt):
-- 省略
def reset(self):
init_h = [np.zeros((1, self.n_lstm)), np.zeros((1, self.n_lstm))]
self.state = init_h
self.lstm.reset_states(init_h)
def save_state(self):
self.stock_state = self.state
def load_state(self):
self.lstm.reset_states(self.stock_state)
保存と読み出し、save_weights(), load_weights()
保存と読み出しは、qnetと変わりません。
class Agt(core.coreAgt):
-- 省略
def save_weights(self, filepath=None):
if filepath is None:
filepath = self.filepath
self.model.save_weights(filepath, overwrite=True)
def load_weights(self, filepath=None):
if filepath is None:
filepath = self.filepath
self.model.load_weights(filepath)
以上で、agt_lstm.py の内容は全てです。
agt_lstm, agt_gru で出来るタスクとできないタスク
agt_lstm, agt_gru は、qnetが解くことのできる silent_ruin, open_field, many_swamp を解くことができます。ruin_1swampもqnetと同じように大体できます。
そして、qnetができなかった、短記憶を必要とする Tmaze_both, Tmaze_either を解くことができます。これが、lstm/gru の成果です。
Tmaze_both です。


Tmaze_either です。
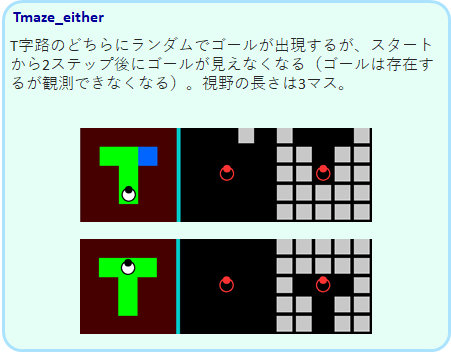

ただし、トレーニングは学習が達成していなくても 5000 step 終了になりますが、学習がいつできるかどうかは確率的です。追加学習のコマンドM で3 回ほど試し、それでもできなかったら、Lで初めからやり直してみてください。筆者は、LSTM, GRU のどちらでもTmaze_both, Tmaze_either ができることを確認しています。
Tmaze_both, Tmaze_either は短期記憶を必要としますがかなりシンプルなタスクです。それにも関わらず、学習は簡単ではありません。
そして、Tmaze よりも複雑になったruin_2swamp は満足に解くことはできません。30000回の学習でも以下のようなパフォーマンスでした。1度行ったゴールにもまた近づいてしまっていることが分かります。2つのゴールを訪れることができたエピソードでも、1度行ったゴールを通り過ぎて2つめのゴールに向かっているので、1度行ったゴールを覚えているわけではなさそうです。
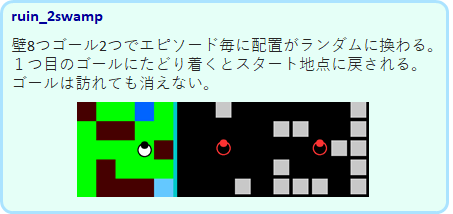

筆者が試した限り、ネットワークのユニット数や層を変えてもパフォーマンスは上がりませんでした。このような問題がなぜ、lstmで出来ないのか、どうすればできるのかを考えることが今後の課題ですね。