この章では、池巡りタスクのプログラムenv_swamptour.pyを例に、一般的な強化学習の問題設定を説明していきます。本記事では、部分観測マルコフ決定問題(POMDP)を扱います。
池巡りタスクを自分でプレイする
池巡りタスクは、パラメータを変えることで、基本の簡単タスクから、ニューラルネットが必要になるタスク、更には、従来の強化学習では解くことができない、短期記憶を必要とするタスクも設定することができます。
env_swamptour.py は、本来はエージェントのプログラムと組み合わせて使いますが、単独で実行すると、あなた自身でプレイすることができます。
では、プロンプト(Anaconda Powershell Prompt)を立ち上げて、
で、仮想環境に入りましょう(仮想環境名がmRLであることを想定)。
で、プログラムを展開したフォルダーに移動します。[プログラムを展開したフォルダ]には実際のパスを書いてください。
とすると、以下のように実行方法が表示されます。
python env_swanptour.py の後に、[task_type]を記述してください、という意味です。タスクタイプには、silent_ruin, open_field など、表示されているものを指定することができます。
まず、
としてみましょう。
以下のようなイメージが表示されます。
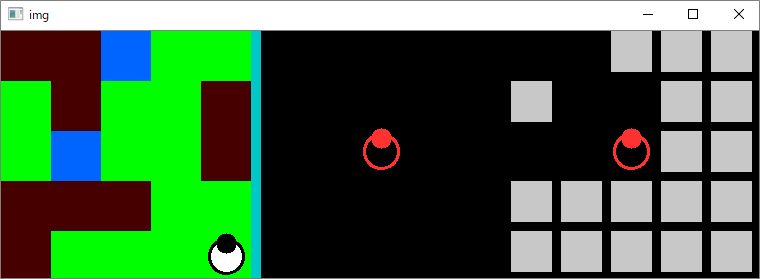
キーボードから中心のキャラクター(ロボット)を操作することができます。
以下のような操作方法がプロンプトに表示されます。
キー操作でロボットが動かせることを確認してみてください。
全てのタスクタイプにおいて、タスクの目的は、タイムアウトになる前に全てのゴール(水色)を訪れることです。
強化学習の問題設定と用語
env_swamptour.py は、[task_type]で様々な難易度のタスクを選択することができますが、このような強化学習の問題を、強化学習では環境(environment)と呼びます。
そして、問題を解く対象、つまり、あなたや強化学習アルゴリズムをエージェント(agent)と呼びます。
環境である「池巡りタスク」は、ロボットを動かす問題です。エージェントは、各ステップにおいて、以下の3つの行動(action)のどれかを実行しロボットを動かします。強化学習の問題設定で必ずしもロボットという概念は必要ありませんが、行動は必ず定義されます。この節では、一般的な強化学習用語を黄色いマーカーで強調することにします。

池巡りタスクでは、ロボットは以下のようなフィールドを動き回ります。
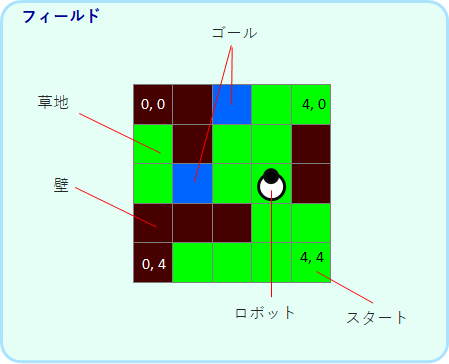
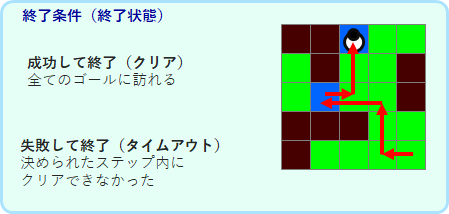
スタートから終了状態になるまで(クリアかタイムアウト)を、エピソードと呼びます。終了状態の後は開始状態に移行し、新しいエピソードが開始されます。エピソードを繰り返しながら、最適な行動を学習することが、エージェントの目的となります。終了状態に来た時には、学習則が少しだけ異なるので実装に注意が必要です。
ここで、環境の状態(state)というものを考えてみます。状態とは、環境の今の状態を記述する全変数の情報としてとらえることができます。
silent_ruin の場合、状態は、[ロボットの位置、方向、各ゴールに到達しているかどうか]の情報になります。
many_swap の場合では、マップがエピソード毎にランダムに変わるので、上記にマップの情報を加えたものが状態になります。
基本的な強化学習の設定では、エージェントは環境から状態を受け取り、その情報をもとに行動を選択します。学習が完了したという状況は、各状態に対して最適な行動を割り当てることができたということになります。
しかしここでは、より実際的な設定として、エージェントは観測(observation)を受け取るとします。
観測は状態から一意に決まる情報ですが※、観測からもとの状態を一意に推測することができない場合が普通です。説明が抽象的になってしまってで分かりにくいと思いますので、silent_ruin の場合で考えます。
※一般的には確率的に決まる、つまり確率分布が一意に決まると考えるのですが、簡単のためここでは決定論的決まるとして説明していきます。
silent_ruin での観測は、自分を中心とした距離2マスまでの範囲のゴールと壁の位置です。
具体的には、ゴールの位置を示した行列と壁の位置を示した行列を連結させた、要素が0か1の行列です。
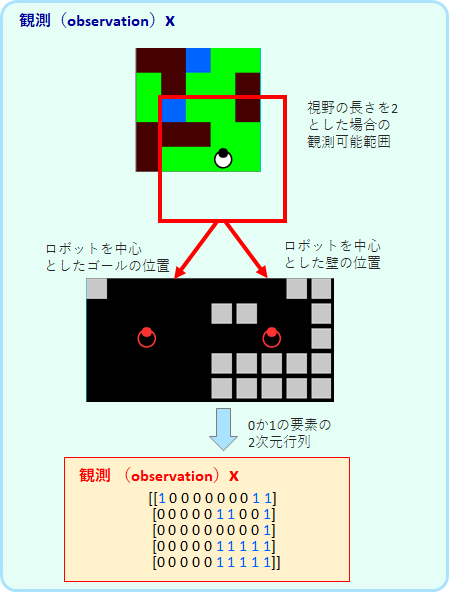
上図の位置にロボットがいる時、視野の範囲に、上のゴールが入っていないことが分かります。よって、上のゴールにすでにたどり着いているかどうかは分かりません(たどり着いたゴールは消える設定です)。つまり、観測は状態の情報を完全には持っていないと言えます。
このような問題設定を、部分観測マルコフ決定過程(POMDP)の問題と呼びます。
これに対し、従来の強化学習のようにエージェントが状態そのものを受け取るとき、マルコフ決定過程(MDP)の問題と呼びます※。
※どのようなものをマルコフ決定過程とよぶかについては、少し数学的な話になるのでここでは説明を省略します。
ちなみに受け取った観測から状態を一意に推定できる場合は、MDPになります。silent_ruinの設定で、ゴールが1つしかない場合にはMDPです。1つしかないゴールは、常に辿り着いていない状態であるので観測する必要はありません。また、マップが固定で似たような地形が2か所にないので、視野が限られていてもその観測パターンから地図のどこにいるかが分かります。つまり、観測から状態を一意に推定できる場合に対応します。
当然ながら、MDPよりもPOMDPの方が難しい問題設定になります。そして、POMDPでも観測できる情報が少なければ少ないほど難易度は高まります。
さて、報酬ですが、silent_ruinでは、ゴールに訪れたら1、壁に当たったら-0.2、それ以外で-0.1(動くコスト)としています。ただし、ゴールには初めて訪れたときのみ1で、2回目以降は-0.1となります。

エージェントの目的は、エピソードが終わるまでの報酬の和(累積報酬和)を最大にする行動を各状態で選べるようにすることです。
タスク自体にも目的があります。silent_ruinでは、全てのゴールに訪れるこことが目的です。しかし、エージェントはそれを知ることはなく、ただ累積報酬和を最大にしようと努めます。つまり、累積報酬和を最大にする行動が、タスクの目的に合うように報酬を設計することが大切になってきます(タスクが達成できるようにどのように報酬を決めるかも一つの研究対象になっています)。
環境とエージェントの相互作用をまとめるとこのようになります。
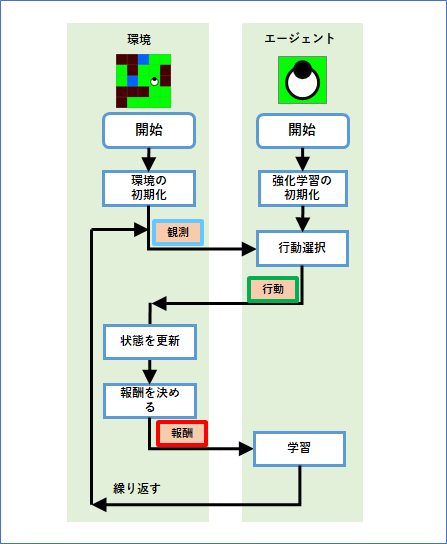
従来の強化学習アルゴリズムが受け取る情報は、「状態」そのものでしたが、今回は状態から決定する「観測」となっていることに注意してください。