memoryRLの使い方の説明です。
一連の流れ
Anaconda Powershell Prompt (以下、簡単にプロンプトと呼ぶことにします)を立ち上げて、
で仮想環境に入ります(仮想環境名がmRLであることを想定)。
でプログラムを展開したフォルダーに移動します。[プログラムを展開したフォルダ]には実際のパスを書いてください。
とすると、以下のように実行方法が表示されます。
説明のように、python sim_swanptour.py の後に3つのパラメータをセットして使います。
qnet (ニューラルネットを使ったQ学習) を使って many_swamp のタスクで 学習を開始するには、以下のようにします。最後のパラメータは、more か Lにします。
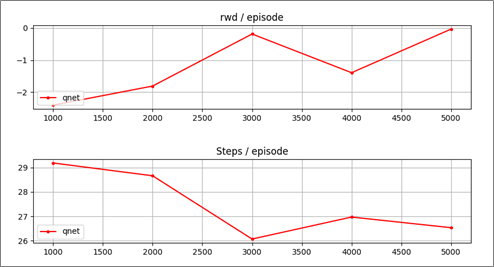
すると、以下のように表示が始まり、5000 stepの学習が行われます。
eval_rwd は、その時の1エピソード中の平均報酬、eval_steps は平均step数です。この値を指標として学習が目標値に進んだときにも学習は終了するようになっています(EARY_STOP)。
最後に学習過程のグラフ(eval_rwd, eval_steps)が表示されます。
[q]を押すとグラフが消え終了します。
学習の結果後の動作アニメーションを見るには、最後のパラメータをanime か Aにします。
100エピソードが終わると終了します。[q]を押すと途中終了します。

アニメーションを見ると、適切に動けていなことが分かります。まだ学習が足りないのです(アニメーションの右側の白黒の図は次章で説明しますが、強化学習アルゴリズムへの入力を表しています)。
そこで、追加学習します。最後のパラメータをmore か Mにして実行します(初めから学習する場合は L を使います)。
これを数回繰り返します。EARY_STOPが表示されて途中終了すると、学習が良いところまで進んだといえます。many_swampは、eval_rwd が1.4以上または、eval_steps が22以下になるとEARY_STOPとなります。
グラフ表示です。
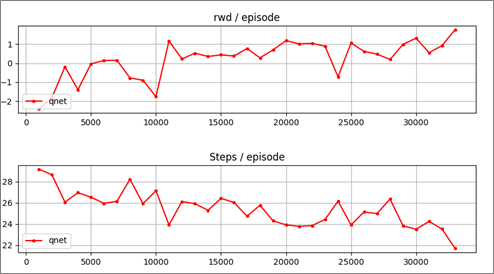
徐々にエピソード当たりのreward が増加し、step数が減少していることが分かります。
アニメーションを見てみましょう。
たまに失敗しますが、だいたいうまくいっているようです。

今までに学習させたグラフを表示するには、最後のパラメータをgraph か Gにします。
以上が池巡り(sim_swamptour.py)の使い方の説明です。
エージェントの種類
[agt_type] で指定できる強化学習アルゴリズム(エージェント)は、 q, qnet, lstm, gru の4種類です。ここではその特徴を簡単に説明します。
q:通常のQ学習
基本のQ学習アルゴリズムです。各観察に対して各行動のQ値を変数(Qテーブル)に保存し、更新していきます。観測値は500個まで登録できる設定にしています。それ以上のパターンが観測されたらメモリーオーバーで強制終了となります。

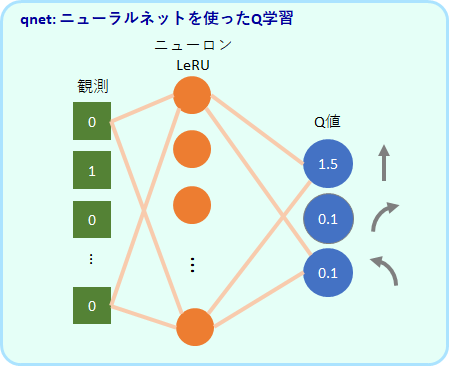
qnet:ニューラルネットを使ったQ学習アルゴリズム
ニューラルネットワークでQ値を出力するよう学習します。入力は観測値で、出力は3つ値です。この3つの値が各行動のQ値に対応します。中間層は64個のReLUユニットです。
未知の観測値に対してもQ値を出力することができます。
lstm/gru: 記憶ユニットを使ったQ学習アルゴリズム
過去の入力にも依存した反応が可能な記憶ユニット(LSTM または GRU)を加えたモデルです。LSTMを使ったアルゴリズムをlstm、GRUを使ったアルゴリズムをGRUと呼んでいます。
qやqnetは、観測値が同じであれば同じ行動しか出力することしかできませんが、このLSTMやGRUを使ったモデルは、過去の入力が異なれば観測値が同じでも異なる行動を出力することが原理的に可能です。
LSTMは自然言語処理のモデルでよく使用されている記憶ユニットですが、GRUはLSTMをシンプルにしたモデルです。
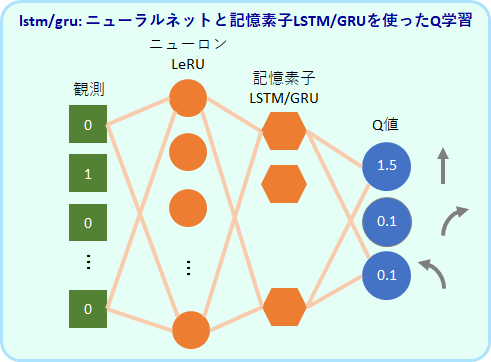
LeRU 64個、LSTMまたはGRU は32個を使用しています。
記憶ユニットを強化学習モデルに組み込む試みは、実に最近になってからであり、その有用性はまだあまりはっきりしていないのではと思っています。この記事では後半でその能力を少し調べていきたいと思います。
ちなみに、gruはlstmよりも学習が早いのではと期待して作ったのですが、memoryRLでのパフォーマンスはあまりかわらなさそうです。
タスクの種類
[task_type] で指定できるタスクは、silent_ruin, open_field, many_swamp, Tmaze_both, Tmaze_either, ruin_1swamp, ruin2swamp の7種類です。ここではその特徴を簡単に説明します。
全タスクで共通のルール
全てのタスクで共通しているのは、ロボットが全てのゴール(青のマス)に訪れたらクリア、というルールです。
アルゴリズムが受け取る情報は、ロボットを中心とした、限られた視野におけるゴールと壁の情報です。各タスクの図の、右側の白黒の図がその情報に対応します。
報酬は、初めてのゴールにたどり着くと+1.0、壁に当たると-0.2、それ以外のステップで-0.1となります。
silent_ruin
ゴールは2か所ありますが、マップは常に同じです。そのために、観測のバリエーションは限られており、q でも学習が可能です。

open_field
壁はありませんが、ゴールの場所はエピソード毎にランダムに変わります。しかし、壁がないので観測のバリエーションは限られており、qでも学習が可能です。

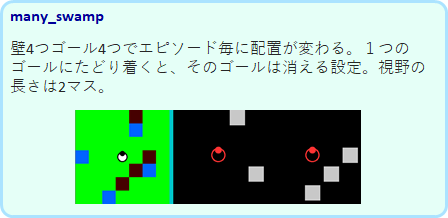
many_swamp
ゴールと壁の位置がエピソード毎にランダムに決まるために、観測のバリエーションが多く、qではメモリーオーバーとなってしまい学習ができません。qnet での学習が可能です。
Tmaze_both
普通の強化学習ではできない問題です。
マップは固定ですが、片方のゴールにたどり着くと、スタート地点に戻されます。そして、訪れたゴールも見えたままです。この状態で、次は別な方のゴールに進まなければなりません。
スタート地点にロボットがいるとき、スタート直後でも、片方のゴールに訪れた後でも同じ観測となります。そのために、同じ観測に対して同じ行動しか選べないqやqnet は、適切な行動を学習種ることができません。過去の履歴で行動を変えることができる gru と lstm のみが学習可能です。

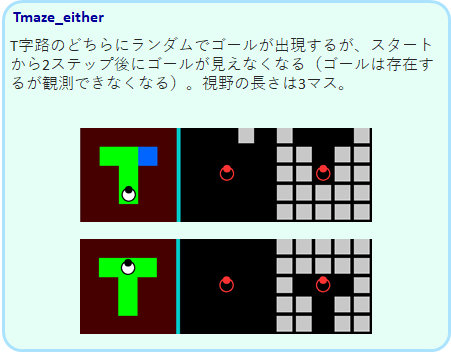
Tmaze_either
このTmazeは、左右のどちらかでゴールが出現しますが、2ステップ後にゴールが見えなくなります。
ロボットは2ステップでT迷路の分岐路に来ることになりますが、ゴールが見えていた方を覚えておき、そちらに向かうことが必要です。このタスクも、qやqnet ではできません。gruとlstmのみが学習可能です。
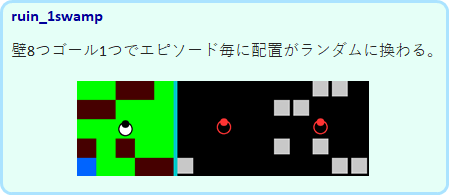
ruin_1swamp
壁が8個、ゴールは1つで、配置がランダムに変わります。回り込んでゴールにたどり着かなければならない場合もあり難易度は高めです。
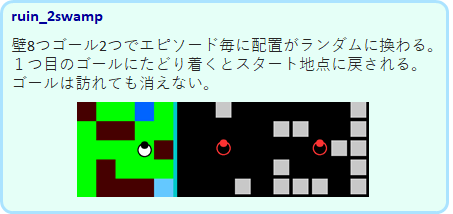
ruin_2swamp
最高難易度のタスクです。ゴールは2つで、片方にたどり着くとスタート地点に戻されます。ゴールは訪れても消えません。Tmaze_both のランダムバージョンのようなタスクです。gruやlstmでも満足にはできませんでした。
ゴールを更に増やしたりフィールドを大きくすることで、更に難易度を上げることができます。将来このようなタスクでもしっかり解けるような強化学習アルゴリズムを開発したいものです。