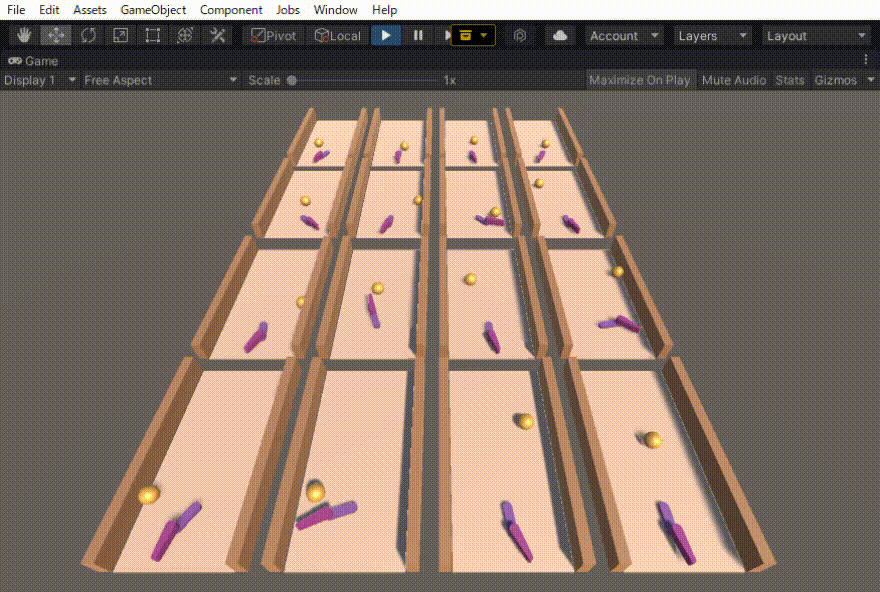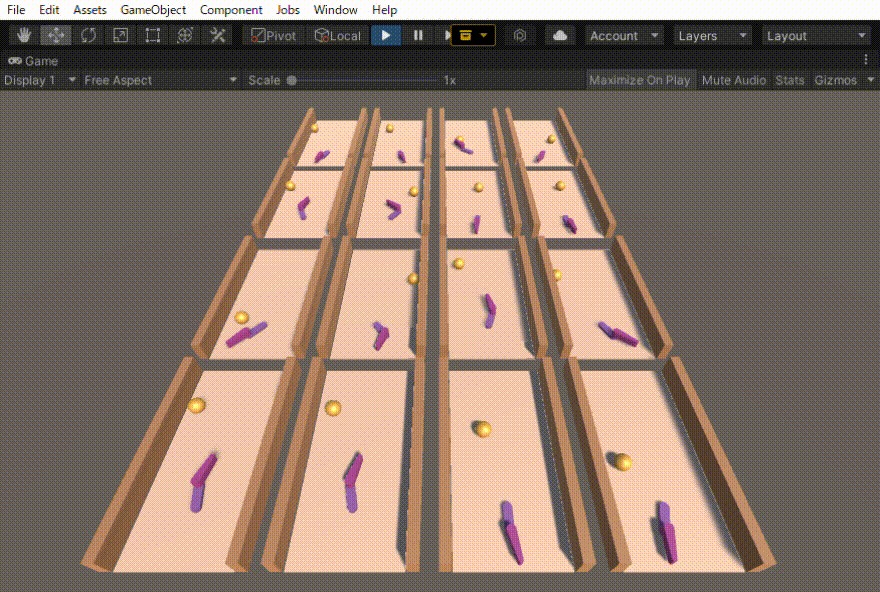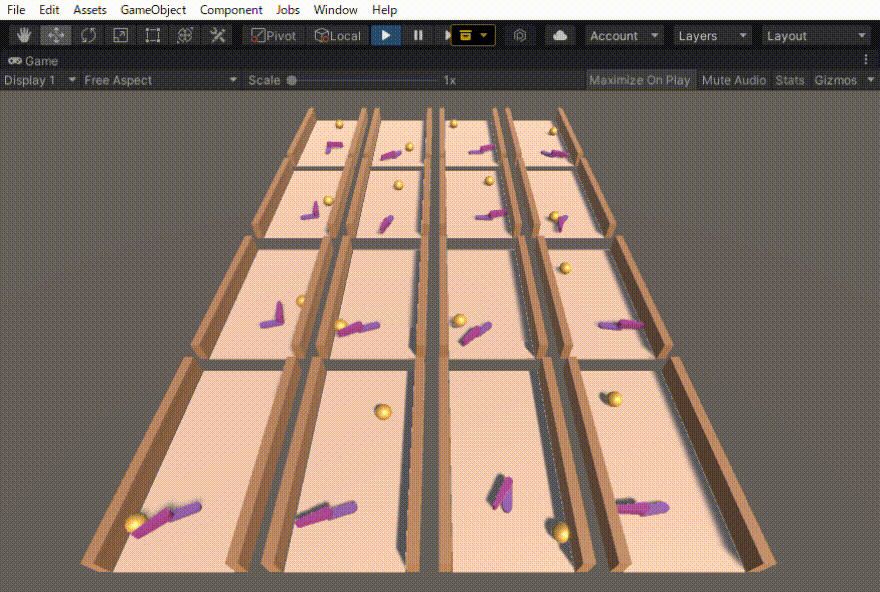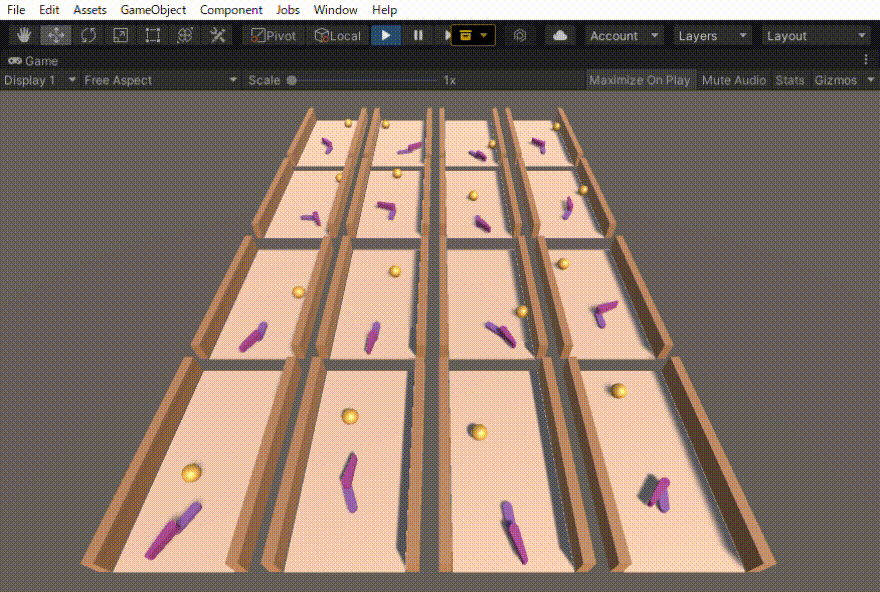
ハンドロンという過去に制作したロボットの動きを強化学習で作りました。その忘備録になります。
ハンドロンとは
ハンドロンは、昔作った卓球ボールを打ち返すロボットです。
この時は、ボールを打つ動作はプログラムで作成しておき、その打つ動作を発動させるタイミングを強化学習で調節させました。
今回の強化学習は、打つ動作は全く組み込まず、動作のすべてを強化学習で作りました。
ゲームオブジェクト
今回のハンドは、前回とほとんど同じで、ArticulationBodyを使った2リンクです(下のTipとbase2というオブジェクトはデバッグ用で関係ないです)。
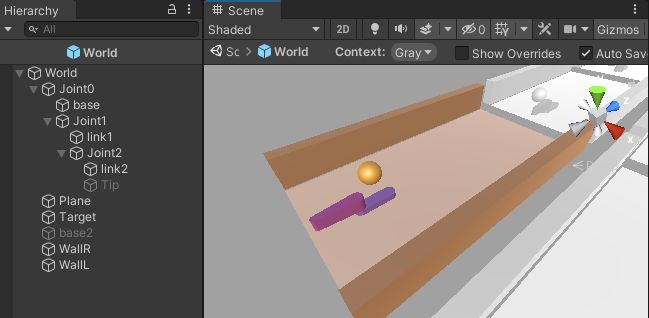
ただし、今回のハンドは、先端にパッドがなく、ハンド全体でボールを打ち返すという仕様です。
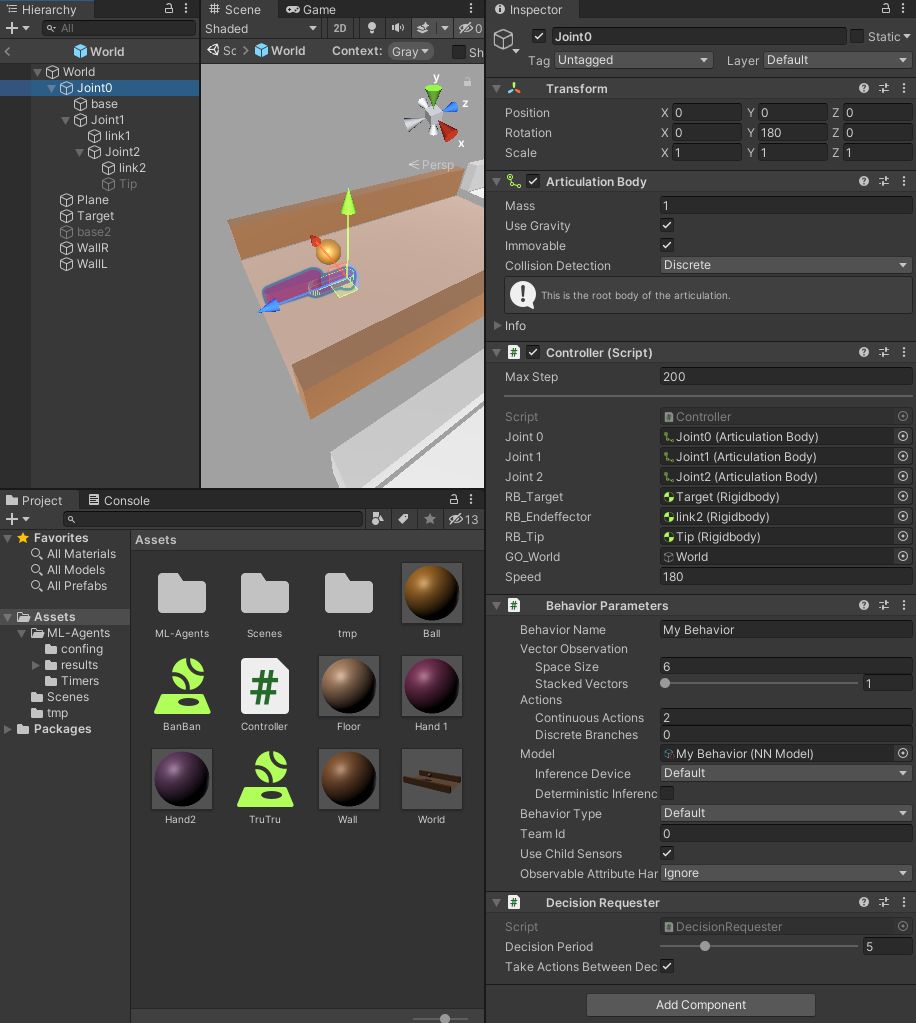
Joint0
根本の設置部分です。Articulation Bodyをaddして、Immovableとしています。
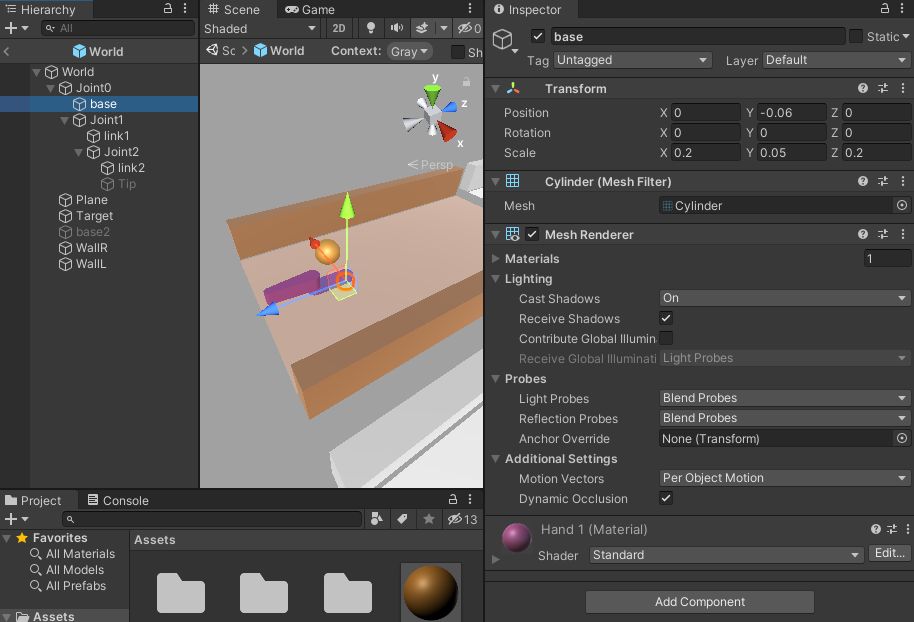
Base
可動部分の実体部分です。
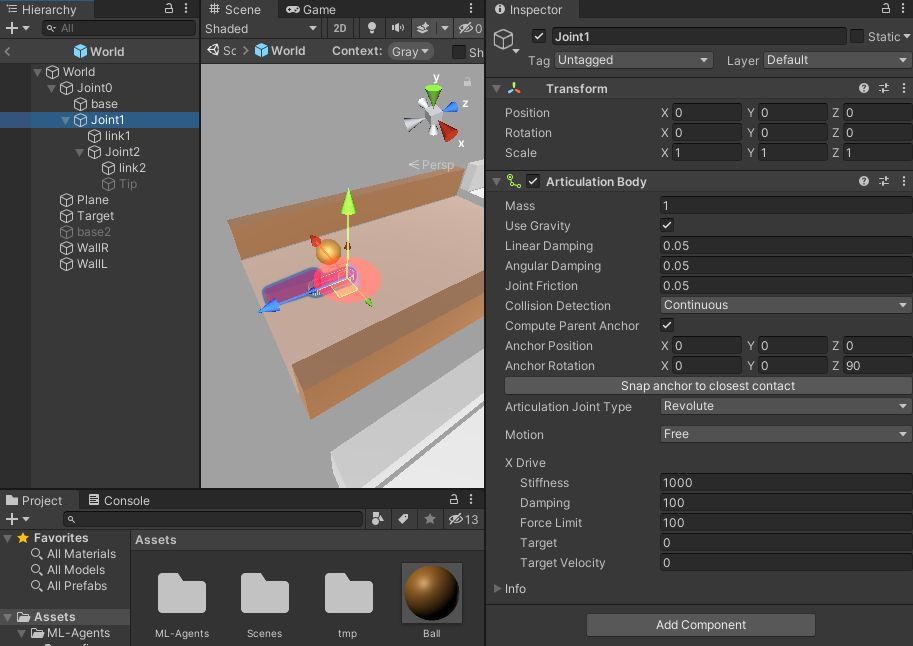
Joint1
根本側の可動部分です。Articulation BodyのRevoluteでJoint0に接続しています。
Link1
Joint1の実体部分です。Mesh Collider とRigidbodyで、玉と衝突できるようにしています。
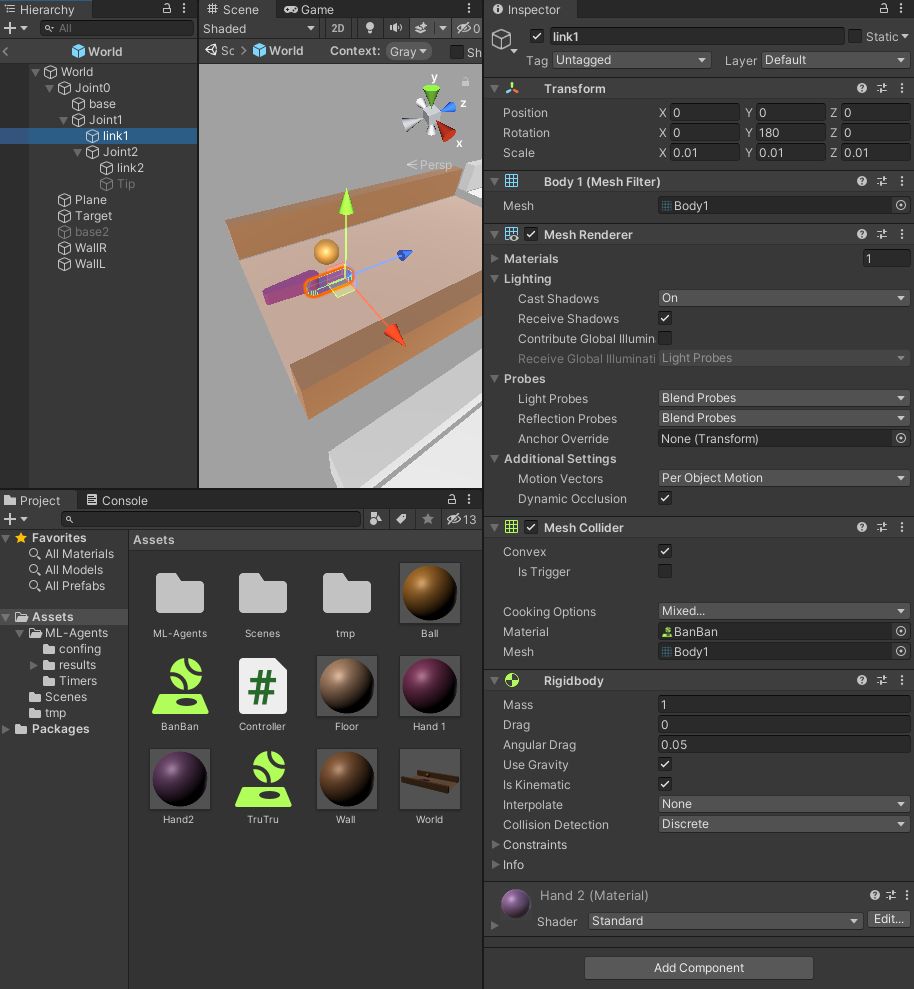
Joint2
先端側の可動部分です。Articulation BodyのRevoluteでJoint1に接続しています。
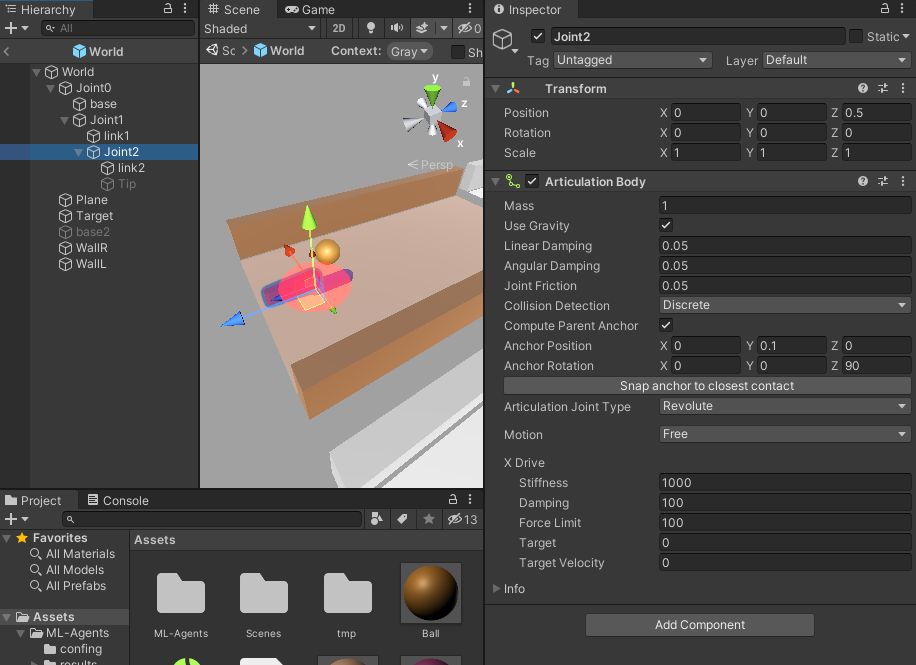
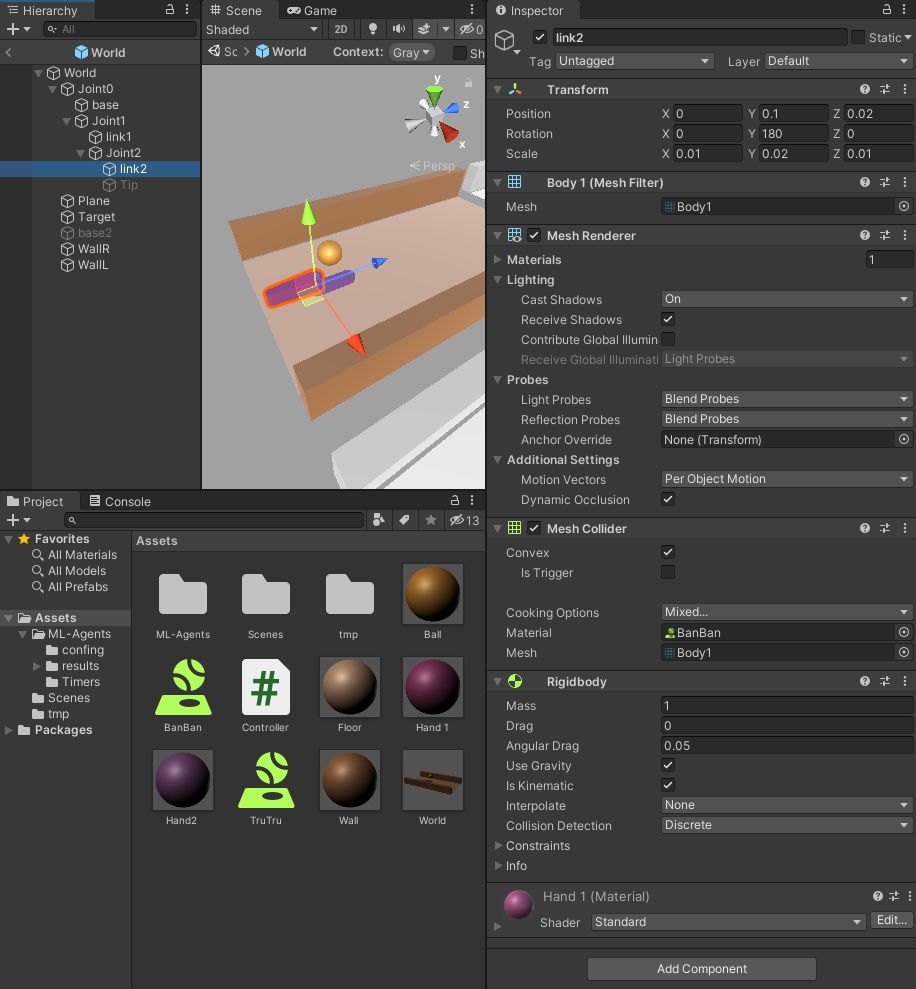
Link2
Joint2の実体部分です。Mesh Collider とRegidbodyで、玉と衝突できるようにしています。
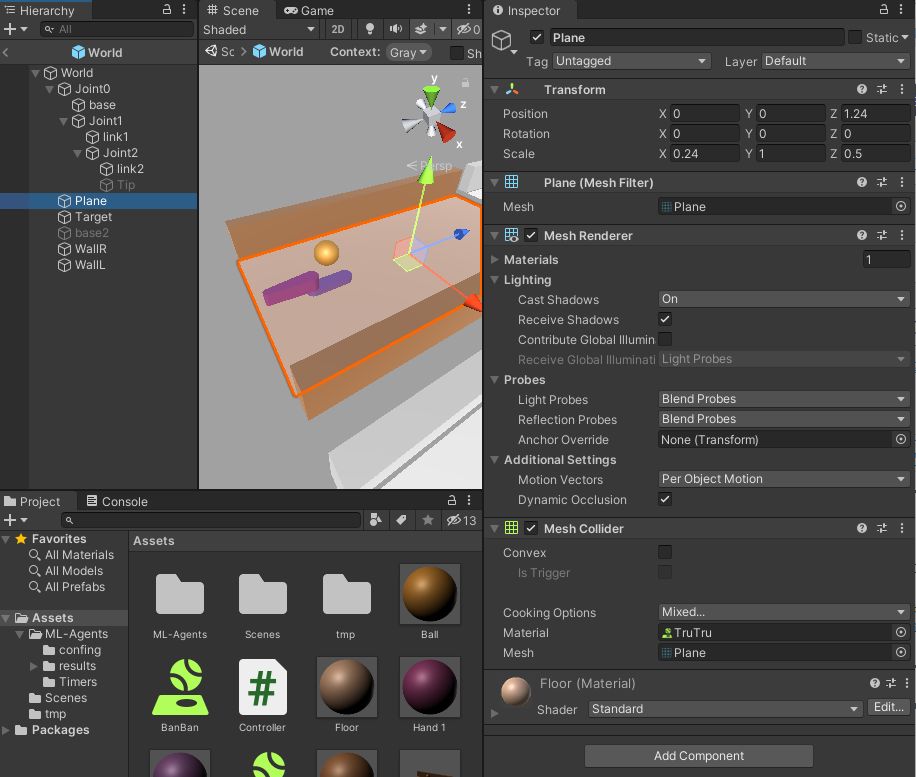
plane
下の床面です。
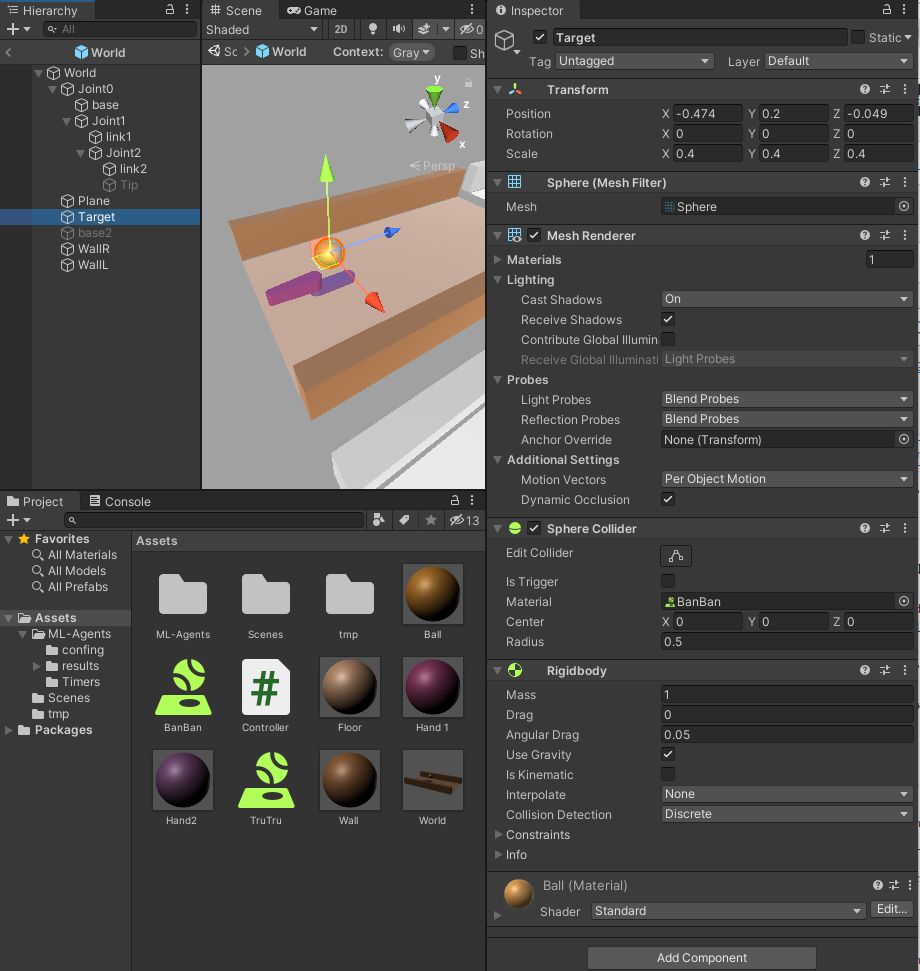
Target
玉です。
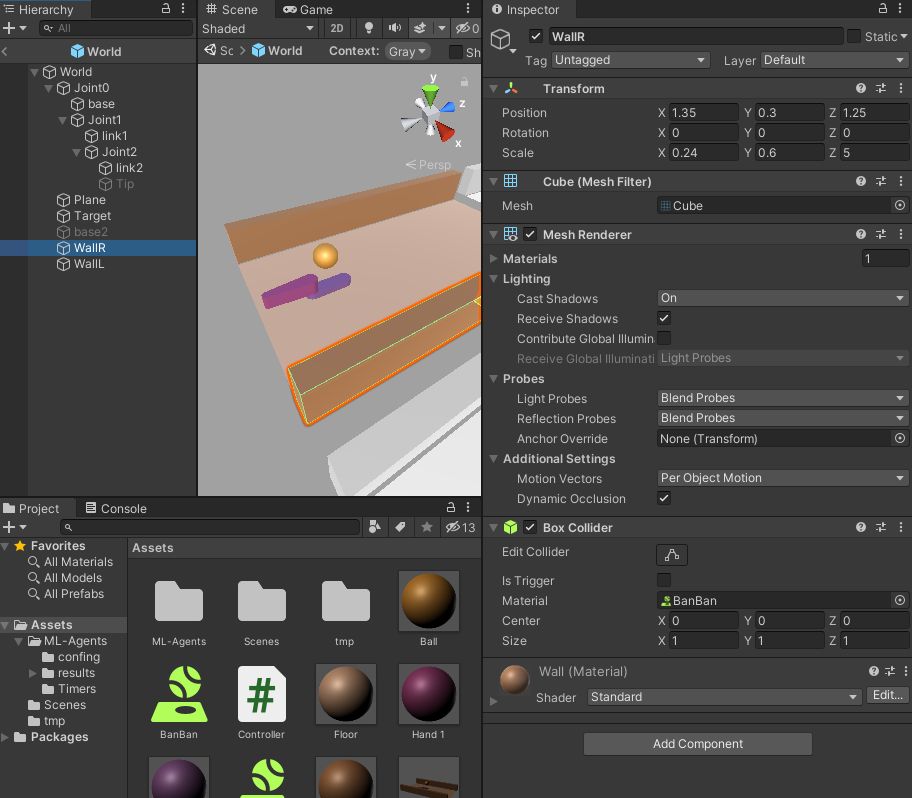
WallR
右側の壁です。左側の壁WallLはX座標にマイナスをつけただけなので省略します。
プログラム
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
using System;
using Random = UnityEngine.Random;
public class Controller : Agent
{
public ArticulationBody Joint1, Joint2;
public Rigidbody RB_Target, RB_Tip;
public GameObject GO_World;
private float angle1, angle2;
private float past_a1, past_a2;
public override void Initialize()
{
// リンクの角度
angle1 = 0;
angle2 = 0;
// 前のステップの行動
past_a1 = 0;
past_a2 = 0;
}
public override void OnEpisodeBegin()
{
past_a1 = 0;
past_a2 = 0;
// 少し前からランダムを入れた方向と速度で転がす
RB_Target.transform.localPosition = new Vector3(
Random.value * 2 - 1, 0.2f, 3);
RB_Target.transform.rotation = default;
RB_Target.velocity = new Vector3(Random.value * 2 - 1, 0, Random.value * 3 -4.0f);
RB_Target.angularVelocity = Vector3.zero;
}
public override void CollectObservations(VectorSensor sensor)
{
// World に対する相対座標
Vector3 joint_pos = GO_World.transform.InverseTransformPoint(Joint2.transform.position);
Vector3 joint_rot = GO_World.transform.InverseTransformDirection(Joint2.transform.eulerAngles);
Vector3 target_pos = GO_World.transform.InverseTransformPoint(RB_Target.transform.position);
// 速度
Vector3 target_v = RB_Target.velocity;
// 観察
sensor.AddObservation(target_pos.x);
sensor.AddObservation(target_pos.z);
sensor.AddObservation(target_v.x);
sensor.AddObservation(target_v.z);
sensor.AddObservation(angle1 / 180); // 180で割って規格化することが重要
sensor.AddObservation(angle2 / 180);
}
public override void OnActionReceived(ActionBuffers actionBuffers)
{
float a1 = actionBuffers.ContinuousActions[0];
float a2 = actionBuffers.ContinuousActions[1];
// 180をかけて角度の単位にする
angle1 = 180 * a1;
angle2 = 180 * a2;
// Joint1を駆動
var xDrive1 = Joint1.xDrive;
xDrive1.target = angle1;
Joint1.xDrive = xDrive1;
// Joint2を駆動
var xDrive2 = Joint2.xDrive;
xDrive2.target = angle2;
Joint2.xDrive = xDrive2;
// 動くことに対するコスト
float cost = - 0.5f * (float) Math.Sqrt(Math.Pow(past_a1 - a1, 2)
+ Math.Pow(past_a2 - a2, 2));
past_a1 = a1;
past_a2 = a2;
AddReward(cost);
// エピソードの終了と報酬
Vector3 target_p = RB_Target.transform.localPosition;
Vector3 target_v = RB_Target.velocity;
if (target_p.z > 3) // 前にはじけた場合
{
AddReward(1 + target_v.z * 0.5f); // 速度が早いほど大きい報酬
EndEpisode();
}
if (target_p.z < -1.5) // 後ろに流してしまった場合
{
EndEpisode();
}
if (target_p.y < -0.1) // 台から落ちた場合
{
EndEpisode();
}
}
public override void Heuristic(in ActionBuffers actionsOut)
{
// マニュアル操作
// Joint1は[a][s][d], Joint2は[z][x][c][/c]で操作する
float a1, a2;
a1 = 0;
a2 = 0;
var continuousActionsOut = actionsOut.ContinuousActions;
if (Input.GetKey(KeyCode.A)){
a1 = 0.5f;
}
if (Input.GetKey(KeyCode.S)){
a1 = -0.5f;
}
if (Input.GetKey(KeyCode.D)){
a1 = -1.0f;
}
if (Input.GetKey(KeyCode.Z)){
a2 = 0.5f;
}
if (Input.GetKey(KeyCode.X)){
a2 = -0.5f;
}
if (Input.GetKey(KeyCode.C)){
a2 = -1.0f;
}
continuousActionsOut[0] = a1;
continuousActionsOut[1] = a2;
}
}
Config.yaml
Asserts/ML-Agents/confing/config.yaml
behaviors:
My Behavior:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 1000000
time_horizon: 64
summary_freq: 10000
実行コマンド
[name]には任意のシミュレーションID
[code]
(mlagents) …\Assets\ML-Agents> mlagents-learn .\config\config.yaml –run-id [name]
[/code]
グラフ描画
[code]
(mlagents) …\Assets\ML-Agents> tensorboard –logdir results –port 6006
[/code]
パラメータチューニングについて
今回は、ここまでできるまでに、思ったよりも時間がかってしまいました。
思うように動かなかったので、リーチングのタスクに戻して動作を確認をしたら、角度の観測値で、180で割っていないというミスがようやく見つかりました。
エピソード毎にハンドを初期位置に戻すと、その位置に戻るまでも連続的に動き(瞬間的に移動させる方法がわからなかった)、その時のボールをはじいてしまう場合がありました。
Jointの相対座標がうまく取れていなかったりもしました。
反省をまとめると、
環境を変えた場合には、簡単なタスクを成功させながら、バグを直したり、環境のパラメータを調節し、徐々に目的のタスクにしていくことが結局のところ近道になる、ということです。
おまけ。報酬と行動
報酬の決め方も結構重要でした。
初めは、ボールがある一定距離前に行ったら報酬=1でエピソード終了とだけしていました。その結果得られた行動は、下の動画の右側の2列のような動きでした。確かにボールを打ち返すのだけれども、無駄な動きが多いです。
そこで、動きに対するコスト(負の報酬)も導入しました。その結果、無駄のない自然な動作(下の動画の左側の2列)を得ることができました。
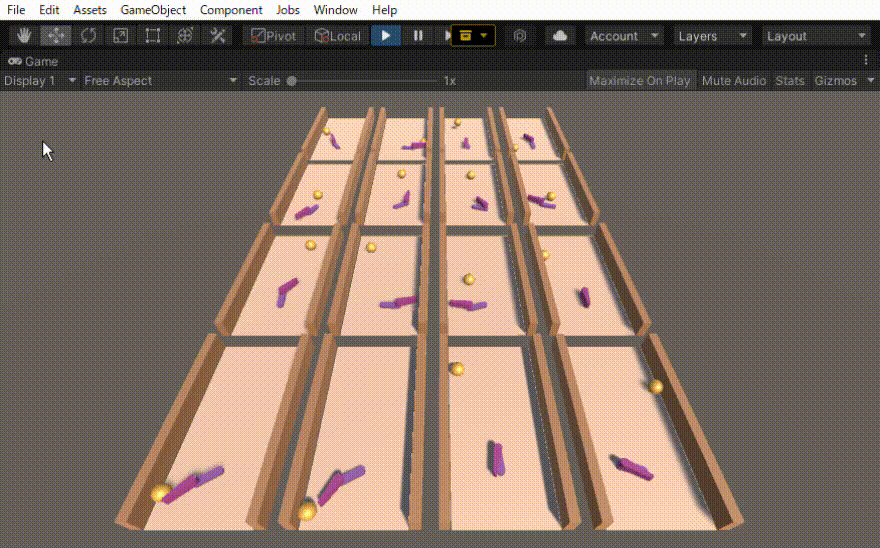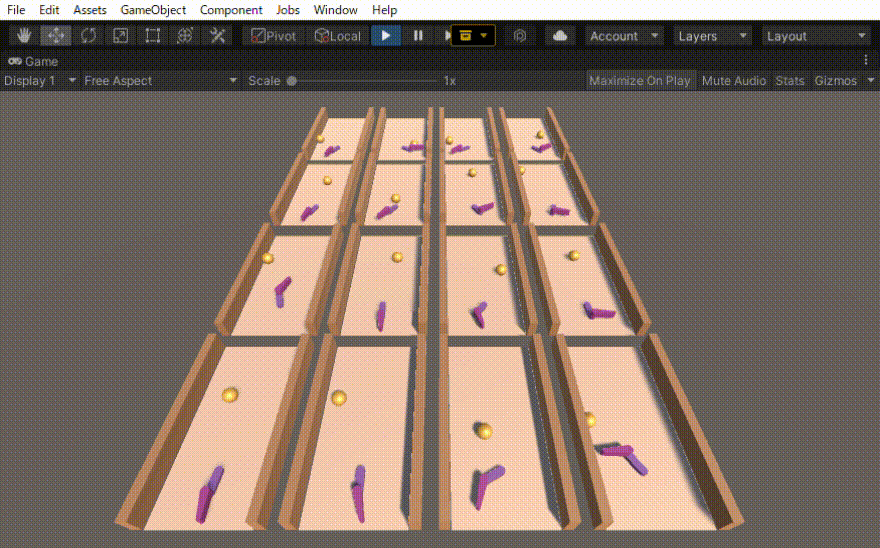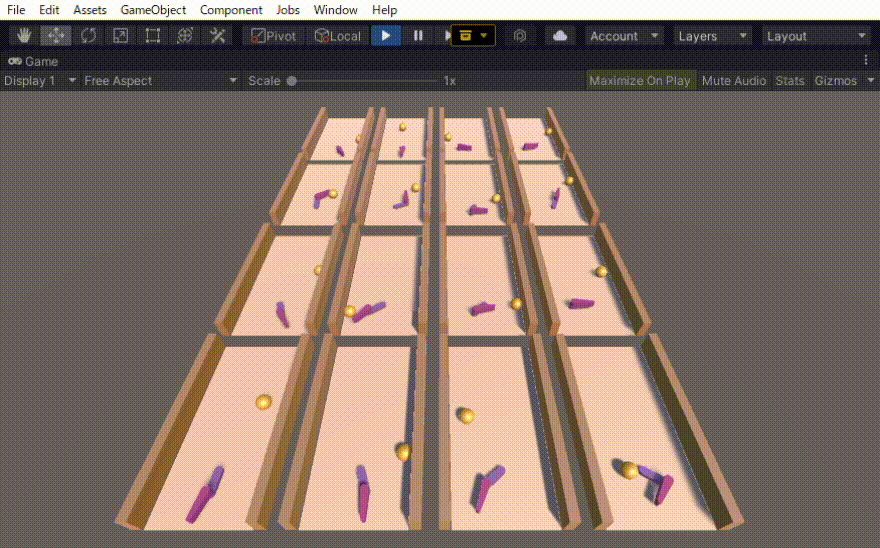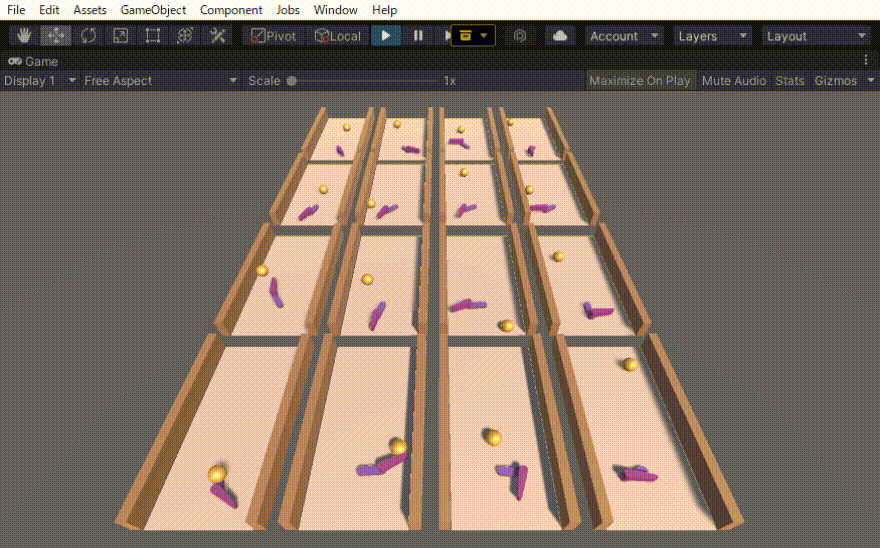
コメントを残す