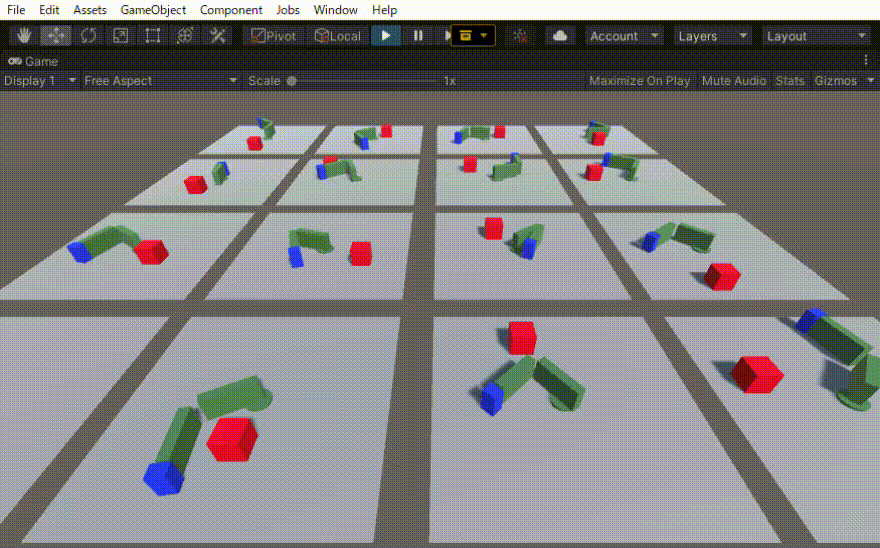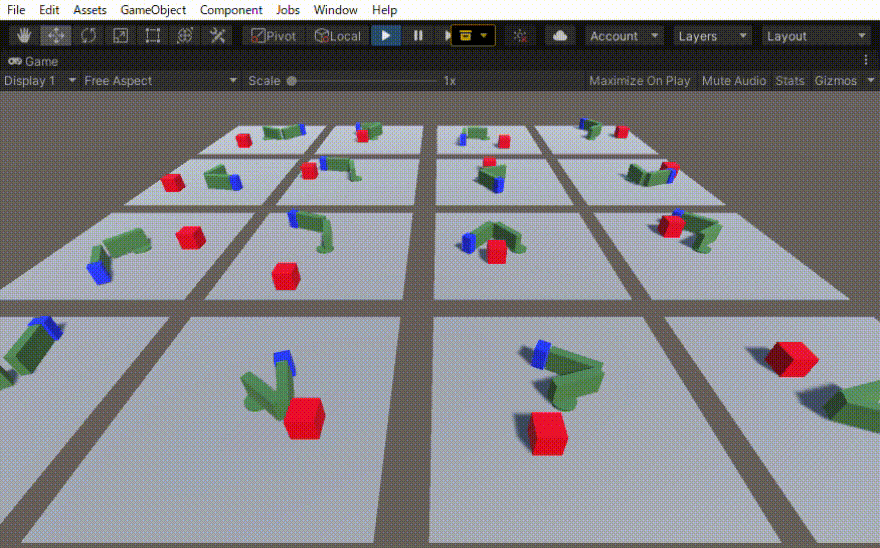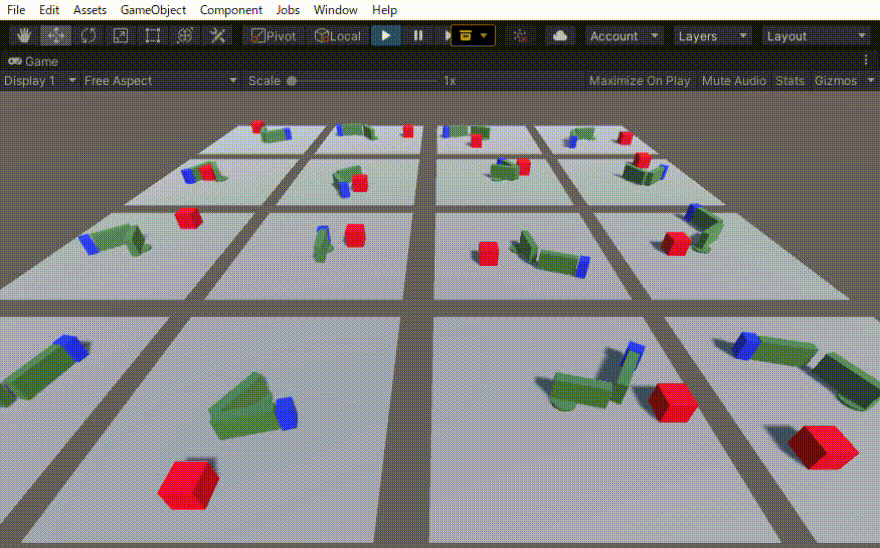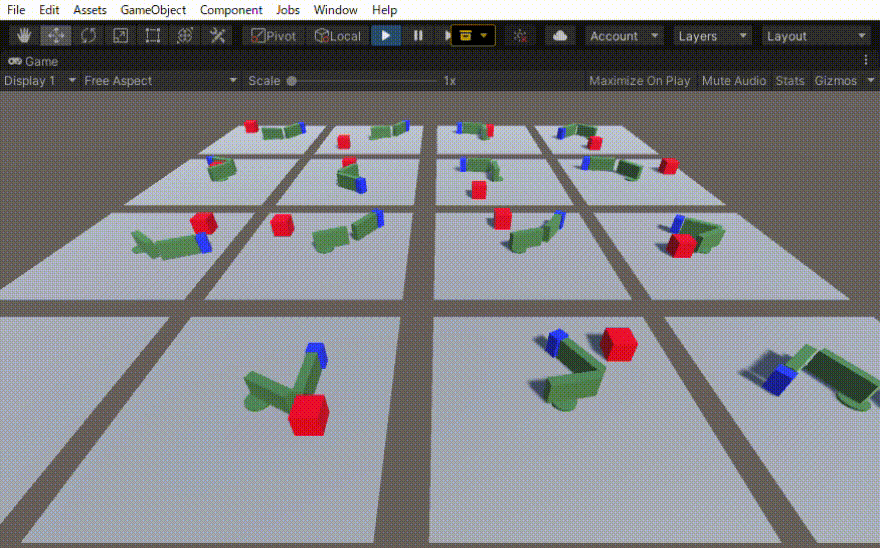
二つのリンクをつなげたハンドのリーチングを学習させました。
この時の設定やプログラムの忘備録です。
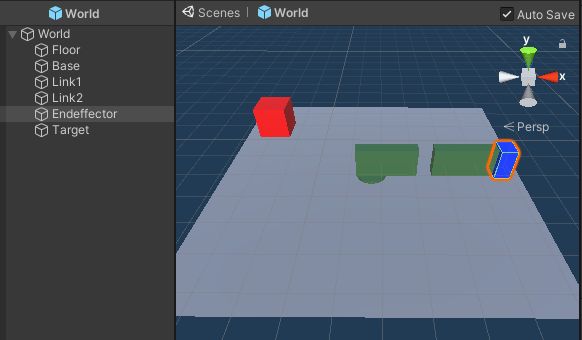
以下、作成したゲームオブジェクトです。
リーてぃんぐのTargetはシンプルです。cube を作っただけで、Rigid Bodyは作っていません。Box Collidorはついています(はじめからついていたんだっけ?)。
ハンドは、中心の土台のBaseと、Link1、Link2、そして青の先端部 Endeffectorからなります。
Link1は、HingeでBaseにつながっています。
Link2は、HingeでLink1につながっています。
Endeffectorは、FixedJointでLink2につながっています。
Link1のHingeの設定です。
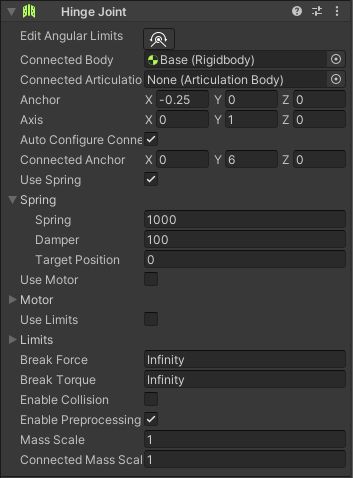
Use Spring にチェックを入れ、Springの設定をしています。
プログラムから、Target Positionを動かすことでハンドを動かします。
Link2も同様です。
Agentの設定をしているのは、Endeffectorです。
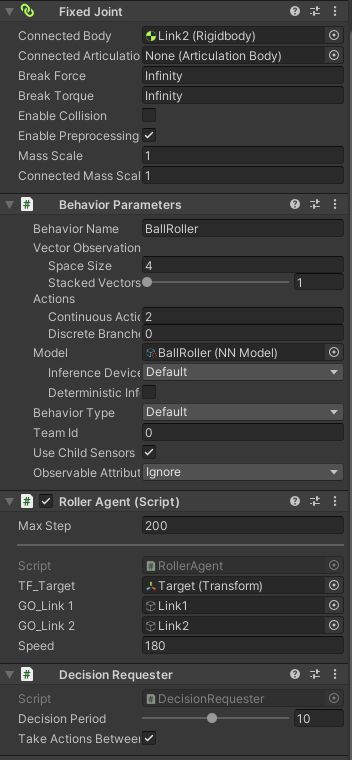
Script は、Roller Agent です(エージェント名が初めにやったもののままでした)。
]using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class RollerAgent : Agent
{
public Transform TF_Target;
public GameObject GO_Link1, GO_Link2;
public float speed;
private Rigidbody RB_Link1, RB_Link2, RB_Endeffector;
private HingeJoint Hinge1, Hinge2;
private Vector3 init_pos1, init_pos2, init_posE;
private Quaternion init_rot1, init_rot2, init_rotE;
private float angle1, angle2;
public override void Initialize()
{
RB_Link1 = GO_Link1.GetComponent<Rigidbody>();
init_pos1 = RB_Link1.transform.localPosition;
init_rot1 = RB_Link1.transform.rotation;
RB_Link2 = GO_Link2.GetComponent<Rigidbody>();
init_pos2 = RB_Link2.transform.localPosition;
init_rot2 = RB_Link2.transform.rotation;
RB_Endeffector = this.GetComponent<Rigidbody>();
init_posE = RB_Endeffector.transform.localPosition;
init_rotE = RB_Endeffector.transform.rotation;
Hinge1 = GO_Link1.GetComponent<HingeJoint>();
Hinge2 = GO_Link2.GetComponent<HingeJoint>();
angle1 = 0;
angle2 = 0;
}
public override void OnEpisodeBegin()
{
if (TF_Target.localPosition.y < 0)
{
RB_Link1.transform.localPosition = init_pos1;
RB_Link2.transform.localPosition = init_pos2;
RB_Endeffector.transform.localPosition = init_posE;
RB_Link1.velocity = Vector3.zero;
RB_Link1.angularVelocity = Vector3.zero;
RB_Link2.velocity = Vector3.zero;
RB_Link2.angularVelocity = Vector3.zero;
RB_Endeffector.velocity = Vector3.zero;
RB_Endeffector.angularVelocity = Vector3.zero;
}
while(true){
TF_Target.localPosition = new Vector3(
Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
float distance = Vector3.Distance(
TF_Target.localPosition, Vector3.zero);
if (distance < 4.00f){
break;
}
}
}
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(TF_Target.localPosition);
// sensor.AddObservation(RB_Endeffector.velocity);
sensor.AddObservation(Hinge1.spring.targetPosition / 180);
sensor.AddObservation(Hinge2.spring.targetPosition / 180);
}
public override void OnActionReceived(ActionBuffers actionBuffers)
{
float a1 = actionBuffers.ContinuousActions[0];
float a2 = actionBuffers.ContinuousActions[1];
angle1 = speed * a1;
angle2 = speed * a2;
if(angle1 < -180){
angle1 += 360;
}
if(angle1 > 180){
angle1 -= 360;
}
if(angle2 < -180){
angle2 += 360;
}
if(angle2 > 180){
angle2 -= 360;
}
JointSpring hs1 = Hinge1.spring;
hs1.targetPosition = angle1;
Hinge1.spring = hs1;
JointSpring hs2 = Hinge2.spring;
hs2.targetPosition = angle2;
Hinge2.spring = hs2;
float distanceToTarget = Vector3.Distance(
TF_Target.localPosition,
RB_Endeffector.transform.localPosition);
if (distanceToTarget < 1.42f)
{
AddReward(1.0f);
EndEpisode();
}
if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
}
public override void Heuristic(in ActionBuffers actionsOut)
{
float a1, a2;
a1 = 0;
a2 = 0;
var continuousActionsOut = actionsOut.ContinuousActions;
if (Input.GetKey(KeyCode.Alpha1)){
a1 = -0.5f;
}
if (Input.GetKey(KeyCode.Alpha2)){
a1 = 0.5f;
}
if (Input.GetKey(KeyCode.Alpha3)){
a2 = -0.5f;
}
if (Input.GetKey(KeyCode.Alpha4)){
a2 = 0.5f;
}
continuousActionsOut[0] = a1;
continuousActionsOut[1] = a2;
}
}
Agentの観測は、Targetの座標と、Hinge1、Hinge2の角度です(Target Position)。
設定ファイルは、
ML-Agents/config/config.yaml に保存しました。
behaviors:
BallRoller:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000
動作を確認してから、
全体をプレファブにして、16個並べました。
[code]
mlagents-learn .\config\config.yaml –run-id=multi
[/code]
PPOを使って学習させたら、すぐに学習できました(10分くらいだったような)。
[code]
mlagents-learn .\config\config.yaml –run-id=multi –resume
[/code]
resumeを使うと、追加で学習させることができます。
コメントを残す