ここでは、環境のプログラムであるenv_swamptour.py の説明と改良するためのポイントを解説します。
プログラム全体の構成
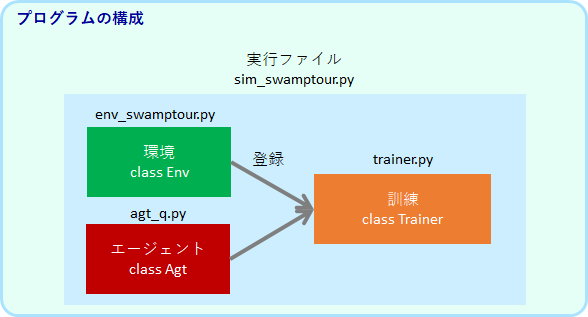
まず、プログラム全体の構成を説明します。
環境のプログラム名はenv_から始まります。env_swamptour.py とenv_corridor.pyの2つあります。env_corridor.py は、lstm/gruの実験用の環境です。これらのファイルの中で、class Env が定義されています。
エージェントのプログラム名は、agt_から始まります。agt_q.py, agt_qnet.py, agt_lstm.py, agt_gru.py の4つあります。それぞれのファイルの中で、class Agt が定義されています。
この環境とエージェントを相互作用させシミュレーションするのが、trainer.py で定義されている class Trainer です。trainer.py は一定stepのトレーニング毎に、エージェントがどれくらいタスクを解けるようになっているかを評価します。評価では、エージェントを学習止め、行動のノイズを0にした状態で、1エピソードにかかるステップと報酬の平均計算します。
実行ファイルであるsim_sawmptour.py は、環境クラスEnvとエージェントクラスAgtのインスタンスを作成し、Trainerのインスタンスに登録され、シミュレーションを実行します。Env、Avt、Trainer へのパラメータの全てが、sim_swamptour.py に集約されています。
環境の抽象クラス coreEnv
環境クラスは、core.py で定義している抽象クラスclass coreEnvを継承しています。
新しく環境のプログラムを作るときには、このcoreEnvを継承し、必要に応じてメソッドを上書きして定義する想定です。coreEnvを眺めると全体の作りが分かると思います。
"""
core.py
EnvとAgtの抽象クラス
"""
from abc import ABCMeta, abstractmethod
class coreEnv(metaclass=ABCMeta):
"""
Envの抽象クラス
"""
def reset(self):
"""
変数を初期化
"""
@abstractmethod
def step(self, action: int):
"""
action に従って、observationを更新
Returns
-------
observation: np.ndarray
reward: int
done: bool
"""
raise NotImplementedError()
@abstractmethod
def render(self):
"""
内部状態に対応したimg を作成
Returns
-------
img: np.ndarray((h, w, 3), type=np.uint8)
"""
raise NotImplementedError()
コード内にも意味をコメントしていますが、簡単にメソッドを説明します。
reset()は、環境の変数を初期化します。エピソード毎に呼ばれます。エージェントをスタート地点に戻すなどの処理を行います。
step(action)は、引数であるactionを使って、現在の環境の変数を変化させ、それに応じた観測observation を返す関数です。環境のプログラムの一番コアとなる部分です。
render()は、今の環境の状態を表した画像を出力するアニメーション表示用の関数です。この出力は人間用のものであり、エージェントには関係しません。
以上の3つが最低必要なEnvのメソッドです。
__init_() と TaskTpye
coreEnvを継承して、env_swamptour.py の中で、池巡りの class Env が定義されています。
__init__() は、インスタンス生成時に必ず実行させる特別なメソッドですが、ここで、フィールドの広さなどタスクのパラメータ16種類を設定することができます。
class Env(core.coreEnv):
def __init__(
self,
field_size=5,
sight_size=3,
max_time=30,
n_wall=1,
n_goal=2,
start_pos=(3, 3),
start_dir=0,
reward_hit_wall = -0.2,
reward_move = -0.1,
reward_goal = 1.0,
maze_type='random',
second_visit_penalty=False,
reset_after_subgoal=True,
erase_visited_goal=False,
wall_observable=True,
step_until_goal_hidden=-1,
):
"""
Parameters
----------
field_size :int
フィールドの大きさ
sight_size: int
視野の大きさ(field_sizeよりも小さくする)
max_time: int
タイムリミット
n_wall: int
壁の数
n_goal: int
ゴールの数
start_pos: (int, int)
スタート地点
start_dir: int (0, 1, 2, or 3)
スタート時の方向
reward_hit_wall: float
壁に当たったときの報酬
reward_move: float
動きのコスト
reward_goal: float
ゴールに到達したときの報酬
maze_type='random': str
迷路タイプ
'random', 'Tmaze', 'Tmaze_large', 'Tmaze_one'
second_visit_penalty: bool
一度到達すると通れなくなる
reset_after_subgoal: bool
ゴールに行くとスタート地点にもどる
wall_observable: bool
壁が観察できる
step_until_goal_hidden: int
-1: ずっと可視
n>0: nステップ後に不可視
"""
# 以下続く
しかし、このパラメータをいちいちセットするのは面倒です。そこで、パラメータのセットに silent_ruin, open_field などの名前をつけ、管理しています。これらは、TaskTypeの列挙型としてenv_swanptour.py の初めで定義しています。
class TaskType(Enum):
"""
タスクタイプの列挙型
"""
silent_ruin = auto()
open_field = auto()
many_swamp = auto()
Tmaze_both = auto()
Tmaze_either = auto()
ruin_1swamp = auto()
ruin_2swamp = auto()
mytask = auto() # <--- 自分タスクを作るとき追加
--- 省略
新しくtasktypeを作る(env_swanptour.pyでできる別なパラメータセットを作る)場合には、上のようにTaskType にオリジナルの名前を加えておきます。
タスクパラメータをセット、set_task_type()
各task_type のパラメータは、以下のset_task_type() で定義されています。このパラメータを変えれば、タスクが変わります。
上記のように、新しいtask_typeとして、mytaskを作る場合には、この並びに、elif task_type == TaskType.mytask: を追加してパラメータをセットすればOKです。
class Env(core.coreEnv):
--- 省略
def set_task_type(self, task_type):
"""
task_type を指定して、parameterを一括設定する
"""
if task_type == TaskType.silent_ruin:
self.field_size = 5
self.sight_size = 2
self.max_time = 25
self.n_wall = None
self.n_goal = None
self.start_pos = None
self.reward_hit_wall = -0.2
self.reward_move = -0.1
self.reward_goal = 1
self.maze_type = 'fixed_maze01'
self.second_visit_penalty = False
self.reset_after_subgoal = False
self.erase_visited_goal = True
self.wall_observable = True
self.step_until_goal_hidden = -1
elif task_type == TaskType.open_field:
self.field_size = 5
self.sight_size = 4
self.max_time = 15
self.n_wall = 0
self.n_goal = 1
self.start_pos = (2, 2)
self.reward_hit_wall = -0.2
self.reward_move = -0.1
self.reward_goal = 1
self.maze_type = 'random'
self.second_visit_penalty = False
self.reset_after_subgoal = True
self.erase_visited_goal = False
self.wall_observable = False
self.step_until_goal_hidden = -1
elif task_type == TaskType.myTask: # <--- 追加
# 追加
--- 省略
迷路の初期化と生成、reset()
reset()は、設定されたパラメータに応じて、迷路を初期化します。
self.mazse_type が 'random' の場合には、フィールドの広さ(self.field_size)、壁の数(self.n_wall)、ゴールの数(self.n_goal)、スタート地点(self.start_pos)に基づいて、それらの配置がランダムにself._make_maze()で、生成され、解くことが可能かを self._maze_check()がチェックし、可能なら採用されます。不可能なら再生成します(壁の数が多すぎて、100回生成しても解くことが可能な迷路ができなかった場合にはエラーとなります)。
self.maze_type が 'Tmaze', 'Tmaze_large', 'Tmaze_one', 'fixed_maze01'の場合には、迷路は変化せずに、ロボットのスタート位置がスタート地点に戻されます。
class Env(core.Env):
--- 省略
def reset(self):
self.done = False
self.reward = None
self.action = None
self.is_first_step = True
self.agt_state = 'move' # render 用
self.time = 0
self.n_visited_goal = 0
if self.maze_type == 'random':
# 迷路をランダム生成
for i in range(100):
self._make_maze()
# 解けないパターンが生成される場合があるのでチェックをする
possible_goal = self._maze_check()
if possible_goal == self.n_goal:
break
if i >= 98:
raise ValueError('迷路が生成できません。壁の数を減らしてください。')
elif self.maze_type == 'Tmaze':
maze = [
'wwwww',
'g g',
'ww ww',
'ww ww',
'wwwww',
]
self.n_goal = 2
self.my_maze(maze, start_pos=(2, 3), start_dir=0)
elif self.maze_type == 'Tmaze_large':
--- 省略
swamptour の改良のポイントはこのようなところでしょうか。
将来の課題タスク
swamptourのパラメータで、簡単な課題も難しい課題も作ることができます。
この章の最後に、今の強化学習では相当難しいだろうというタスクを作ってみました。下の動画gifでロボットを動かしているのは筆者です。
まず、以下のタスクです。一見準備してある、many_swamp と似ているのですが、訪れた池が消えません(右側では人に分かるように色を薄くしていますが、エージェントの観測情報からその区別がつきません)。エージェントは、自分が訪れた池を記憶し、訪れていない池をめざなくてはなりません。そして、最短経路で巡回することが最適解になります。

設定は以下のようになります。
class Env(core.coreEnv):
--- 省略
def set_task_type(self, task_type):
"""
task_type を指定して、parameterを一括設定する
"""
--- 省略
elif task_type == TaskType.myTask:
self.field_size = 10
self.sight_size = 3
self.max_time = 200
self.n_wall = 10
self.n_goal = 5
self.start_pos = (4, 4)
self.reward_hit_wall = -0.2
self.reward_move = -0.1
self.reward_goal = 1
self.maze_type = 'random'
self.second_visit_penalty = False
self.reset_after_subgoal = False
self.erase_visited_goal = False
self.wall_observable = True
self.step_until_goal_hidden = -1
次のタスクは、ランダムに配置された5つの池が、開始後3ステップに見えなくなってしまうという設定です。池の出た位置と、その池に訪れたかどうかを覚える必要があります。人でもかなり難しいです。

設定は以下のようになります。
class Env(core.coreEnv):
--- 省略
def set_task_type(self, task_type):
"""
task_type を指定して、parameterを一括設定する
"""
--- 省略
elif task_type == TaskType.myTask:
self.field_size = 8
self.sight_size = 3
self.max_time = 200
self.n_wall = 3
self.n_goal = 5
self.start_pos = (3, 3)
self.reward_hit_wall = -0.2
self.reward_move = -0.1
self.reward_goal = 1
self.maze_type = 'random'
self.second_visit_penalty = False
self.reset_after_subgoal = False
self.erase_visited_goal = False
self.wall_observable = True
self.step_until_goal_hidden = 3
将来、このような問題も解けるアルゴリズムを考え出したいものです。