stable diffusion はオープンソースの画像生成プログラムです。
stable diffusion の仕組みは、hugging face のブログで説明があります。下の図は、リンクのブログからの転載です。
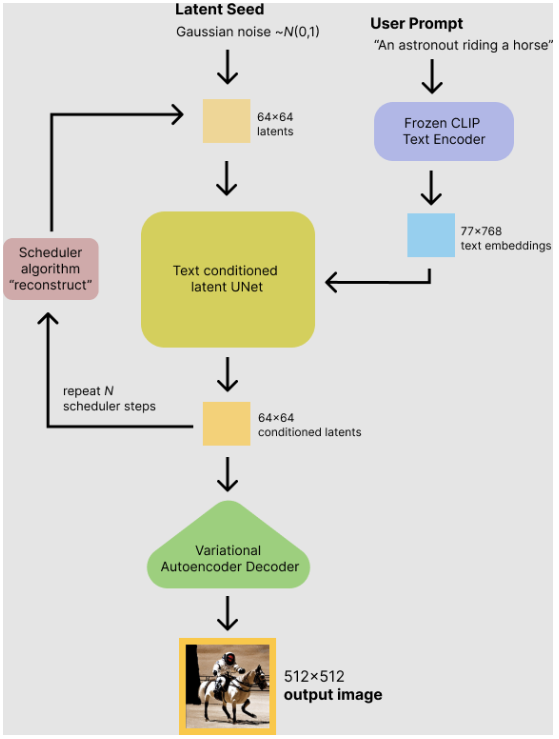
ソースコードはこちらからDLして動かすことができます(参考 環境構築の覚書)。
テキストから画像を生成する実行ファイルはscript/txt2img.py です(コードはこれ)。
中を見ると、実行時の引数でいろいろなチューニングをするために、理解するためには少し煩雑です。そこで、引数は固定して、実行できる最小限のシンプルバージョンに整えましたので、ここで覚書的に残します。
以降、jupyter notebook で動かすことを想定しています。
まず、使用するパッケージのインポートをします。
import torch import numpy as np from omegaconf import OmegaConf from PIL import Image from einops import rearrange from pytorch_lightning import seed_everything from ldm.util import instantiate_from_config from ldm.models.diffusion.plms import PLMSSampler from ldm.models.diffusion.ddim import DDIMSampler
次に、中で使用する関数を定義します。オリジナルにはたくさん関数が定義されていますが、シンプルバージョンで必要なものはモデルをロードするための以下の関数のみです。
def load_model_from_config(config, ckpt, verbose=False):
print(f"Loading model from {ckpt}")
pl_sd = torch.load(ckpt, map_location="cpu")
if "global_step" in pl_sd:
print(f"Global Step: {pl_sd['global_step']}")
sd = pl_sd["state_dict"]
model = instantiate_from_config(config.model)
m, u = model.load_state_dict(sd, strict=False)
if len(m) > 0 and verbose:
print("missing keys:")
print(m)
if len(u) > 0 and verbose:
print("unexpected keys:")
print(u)
model.cuda()
model.eval()
return model
次は、パラメータの設定です。オリジナルでは実行時のオプションでパラメータを指定できるようになっていますが、ここではoptというクラスを作り、クラス変数にパラメータ値を定義するようにしました。画像サイズは、横512、縦256 としています。
class opt:
prompt='Colorful cocktails by the pool' # プロンプト
seed=10 # 乱数のシード値
ddim_eta=0.0 # 0.0でサンプリングが決定的になる
ddim_steps=50 # ddimサンプル数 n_iterとの違い不明
f=8 # ダウンサンプリングファクター
scale=7.5 # unconditional guidance scale
C=4 # 潜在変数のチャンネル数
H=256 # 出力画像の縦の長さ
W=512 # 出力画像の横の長さ
n_samples=1 # 1つのプロンプトから生成する画像の数
n_iter=0 # 意味分からず。デフォルトでは2
ckpt='sd-v1-4.ckpt' # HuggingFaceからDLしたモデルのパス
config='configs/stable-diffusion/v1-inference.yaml' # パラメータファイルのパス
outdir='outputs/txt2img-samples' # 出力フォルダー
precision='autocast'
n_rows=0
from_file=None
dpm_solver=False
fixed_code=False
laion400m=False
skip_grid=False
skip_save=False
次のコードでモデルのロードします。自分のPC(Core-i5-11400F, GeForce RTX 3060Ti, 8GB)では20秒くらいかかりました。
print("モデルのロード----------")
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, 'sd-v1-4.ckpt')
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
ここからが画像生成のプロセスです。
まず、文章であるプロンプトを数値行列に変換したtext embeddings (77×768)を作ります。この計算はほとんど時間はかかりません。
print("プロンプトから潜在変数を作成----------")
seed_everything(opt.seed) # seed値
c = model.get_learned_conditioning(opt.prompt) # promptからc(c.size=[1,77,768])を生成
ここが画像生成のコア部分です。ガウスノイズの行列からノイズ除去の処理を繰り返して、text embeddings に対応するconditioned latents (潜在変数 4 x 32 x 64)を作ります。自分のPCでは10秒くらいかかりました。
print("潜在変数を条件にしてサンプリング----------") # 30秒程かかる
# sampler = DDIMSampler(model) # DDIMを使用する場合
sampler = PLMSSampler(model) # PLMSを使用する場合
shape = [opt.C, opt.H // opt.f, opt.W // opt.f] # shape = [4, 32, 64]
batch_size = opt.n_samples
uc = model.get_learned_conditioning(batch_size * [""])
start_code = None
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
# samples_ddimが潜在変数。samples_ddim.size = [1, 4 ,32, 64]
conditioned latents から、Variational Autoencoder Decoder でoutput image (生成画像 256 x 512 x 3)を作ります。この計算はほとんど時間はかかりません。
print("潜在変数から、画像を作成----------") # 一瞬
x_samples_ddim = model.decode_first_stage(samples_ddim)
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
# x_samples_ddimが生成された画像 x_samples_ddim.size=(1, 256, 512, 3)
最後、画像を表示します(jupyter notebook で表示することを想定しています)。
print("画像表示----------") # 一瞬
x_checked_image = x_samples_ddim
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
x_sample = x_checked_image_torch[0]
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
# 結果の表示
display(img)
「プールサイドのカラフルなカクテル ’Colorful cocktails by the pool’」というプロンプトから生成された画像です。

ここまでのスクリプトをつなげたものはこちら。
import torch
import numpy as np
from omegaconf import OmegaConf
from PIL import Image
from einops import rearrange
from pytorch_lightning import seed_everything
from ldm.util import instantiate_from_config
from ldm.models.diffusion.plms import PLMSSampler
from ldm.models.diffusion.ddim import DDIMSampler
def load_model_from_config(config, ckpt, verbose=False):
print(f"Loading model from {ckpt}")
pl_sd = torch.load(ckpt, map_location="cpu")
if "global_step" in pl_sd:
print(f"Global Step: {pl_sd['global_step']}")
sd = pl_sd["state_dict"]
model = instantiate_from_config(config.model)
m, u = model.load_state_dict(sd, strict=False)
if len(m) > 0 and verbose:
print("missing keys:")
print(m)
if len(u) > 0 and verbose:
print("unexpected keys:")
print(u)
model.cuda()
model.eval()
return model
class opt:
prompt='Colorful cocktails by the pool' # プロンプト
seed=10 # 乱数のシード値
ddim_eta=0.0 # 0.0でサンプリングが決定的になる
ddim_steps=50 # ddimサンプル数 n_iterとの違い不明
f=8 # ダウンサンプリングファクター
scale=7.5 # unconditional guidance scale
C=4 # 潜在変数のチャンネル数
H=256 # 出力画像の縦の長さ
W=512 # 出力画像の横の長さ
n_samples=1 # 1つのプロンプトから生成する画像の数
n_iter=0 # 意味分からず。デフォルトでは2
ckpt='sd-v1-4.ckpt' # HuggingFaceからDLしたモデルのパス
config='configs/stable-diffusion/v1-inference.yaml' # パラメータファイルのパス
outdir='outputs/txt2img-samples' # 出力フォルダー
precision='autocast'
n_rows=0
from_file=None
dpm_solver=False
fixed_code=False
laion400m=False
skip_grid=False
skip_save=False
print("モデルのロード----------")
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, 'sd-v1-4.ckpt')
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
print("プロンプトから潜在変数を作成----------")
seed_everything(opt.seed) # seed値
c = model.get_learned_conditioning(opt.prompt) # promptからc(c.size=[1,77,768])を生成
print("潜在変数を条件にしてサンプリング----------") # 30秒程かかる
# sampler = DDIMSampler(model) # DDIMを使用する場合
sampler = PLMSSampler(model) # PLMSを使用する場合
shape = [opt.C, opt.H // opt.f, opt.W // opt.f] # shape = [4, 32, 64]
batch_size = opt.n_samples
uc = model.get_learned_conditioning(batch_size * [""])
start_code = None
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
# samples_ddimが潜在変数。samples_ddim.size = [1, 4 ,32, 64]
print("潜在変数から、画像を作成----------") # 一瞬
x_samples_ddim = model.decode_first_stage(samples_ddim)
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
# x_samples_ddimが生成された画像 x_samples_ddim.size=(1, 256, 512, 3)
print("画像表示----------") # 一瞬
x_checked_image = x_samples_ddim
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
x_sample = x_checked_image_torch[0]
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
# 結果の表示
display(img)
コメントを残す