最近株について興味があり調べたりしています。ここでは、Pythonによるデータ収集と整理の方法の覚書としてまとめました。
以下のpythonのコードは、jupyter notebook を想定しています。
株価データの取得
以下で、企業コードと期間を指定して株価の情報が得られます。
import pandas_datareader as pdr
code = 9434 # ソフトバンクの銘柄コード
start = "2016-01-01"
end = "2023-02-24"
df = pdr.DataReader(f"{code}.JP", "stooq", start, end).sort_index()
df
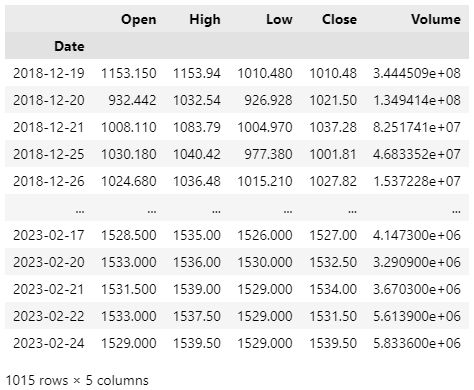
Openは始値、Highは高値、Lowは安値、Closeは終値、Volumeは出来高です。
分析にはCloseを良く用います。
全銘柄コードの取得
上の方法は、会社の銘柄コードを知っていないと使えませんが、下のコードで、銘柄コードの表を日本取引グループから取得し、ローカルに”stock_j.xls”として保存できます。
import requests
import pandas as pd
url = "https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls"
r = requests.get(url)
with open('stock_j.xls', 'wb') as output:
output.write(r.content)
stock_j.xlsを読み込むときには、以下のようにします。
stocklist = pd.read_excel("./stock_j.xls")
stocklist

なんと、4244もの企業が登録されています。
初めから全ての企業に対して分析するよりは、まずは、代表的な企業に絞って分析した方がよさそうです。
TOPIXコア30の株価データをまとめてDLする
TOPIXコア30とは、東証1部銘柄で、時価総額、流動性の特に高い30銘柄。この企業に絞ってデータベースを作ります。
以降、Core30と呼ぶことにします。
# CORE30の銘柄チャートの取得と保存 ----------
import pandas_datareader as pdr
import pandas as pd
import os
# to_excel()でworningが出るので非表示にする
import warnings
warnings.simplefilter("ignore")
# 設定 -----
target_type = "TOPIX Core30" # 絞り込む銘柄の規模区分
dir_name = "./dat_core30" # 保存ディレクトリ
start = "2016-01-01"
end = "2023-02-24"
# 取得関数の定義 -----
def get_stock_data(code, start, end):
return pdr.DataReader(f"{code}.JP", "stooq", start=start, end=end).sort_index()
# ターゲット銘柄の抽出 -----
stocklist = pd.read_excel("./stock_j.xls")
df = stocklist.query(f"規模区分 == '{target_type}'")
# 保存ディレクトリ(dir_name)の作成 -----
if not os.path.exists(dir_name):
os.makedirs(dir_name)
# 各株価データを"番号_コード_銘柄名_17業種区分.xls"のファイル名で保存
for i, code in enumerate(df["コード"]):
print(f"{i}:{code}, ", end="")
code = df.iloc[i, df.columns.get_loc("コード")]
cname =df.iloc[i, df.columns.get_loc("銘柄名")]
cclass =df.iloc[i, df.columns.get_loc("17業種区分")]
fname = f"{dir_name}/{i:05d}_{code}_{cname}_{cclass}.xls"
data = get_stock_data(code, start=start, end=end)
data.to_excel(fname, index=True, header=True)
データが保存されたディレクトリ。大企業の名前がずらりと並んでいます。
Core30のCloseデータを1つのデータフレームdf_allにまとめて保存
以下のコードで、30社のcloseデータを1つの表にまとめて”all_close.xls” として保存します。
import pandas as pd
import glob
# 設定
dir_name = "./dat_core30" # 保存ディレクトリ
# 通し番号のみを指定してデータを読み込む関数の定義
def get_saved_data(idx, dirname):
fname = glob.glob(f"{dir_name}/{idx:05d}_*.xls")[0]
df = pd.read_excel(fname, index_col=0)
return fname, df
# データのまとめ
df_all = pd.DataFrame()
n_file = 30
for idx in range(n_file):
fname, df = get_saved_data(idx, dir_name)
df_all = pd.concat([df_all, df["Close"]], axis=1)
df_all.rename(columns={"Close": f"c{idx}"}, inplace=True)
# df_allの保存 "all_close.xls"
df_all.to_excel(f"{dir_name}/all_close.xls", index=True, header=True)
df_all
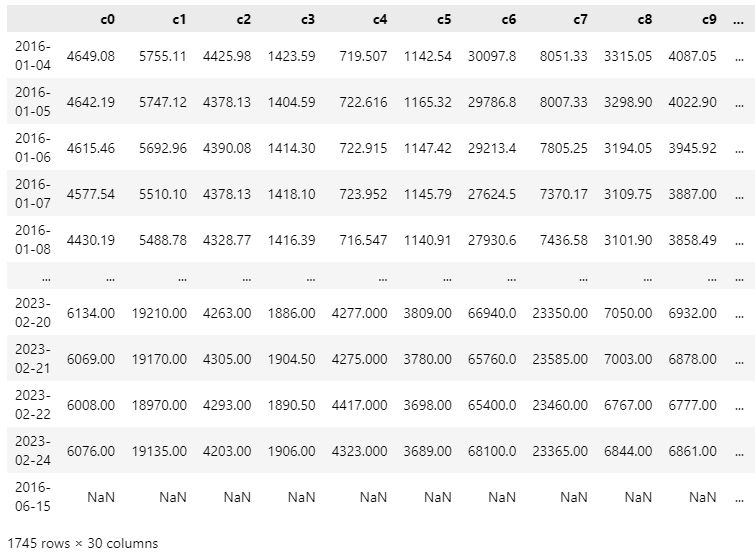
しかし、以下で欠損値の数を確かめると、758個もあります。
print(df_all.isnull().sum().sum()) # 758
調べてみると、c28に730個の欠損値があり、2016-06-15にすべての銘柄で欠損値が起きていました。
よってc28は除去、2016-06-15の行も除去します。
# 欠損値が730もあるc28を削除
df_all.drop("c28", axis=1, inplace=True)
# 全てがNaNとなっている2016-06-15 を削除
df_nan = df_all.query("c0.isnull()", engine="python")
for idx in df_nan.index:
df_all.drop(idx, axis=0, inplace=True)
欠損値がなくなったdf_allを”all_close.xls”として保存します。
print(df_all.isnull().sum().sum()) # 0になっている
df_all.to_excel(f"{dir_name}/all_close.xls", index=True, header=True)
グラフ
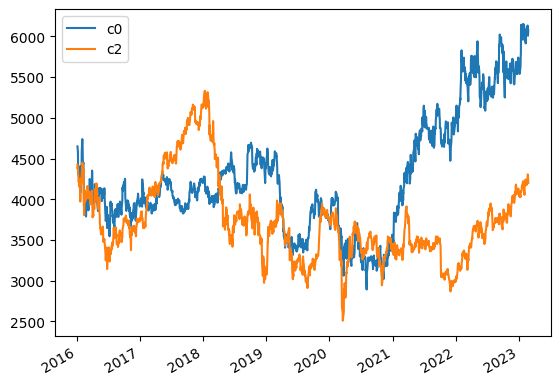
pandas は、以下のようにしてデータを簡単にグラフで描画することができます。
df_all[["c0", "c2"]].plot()
コメントを残す