さて、ここからは振り子の振り上げを自動で行うことを考える。最適な行動を試行錯誤で学習する「強化学習」というアルゴリズムを実装する。
強化学習の問題設定
まずは問題の整理から。問題設定を以下に図示した。
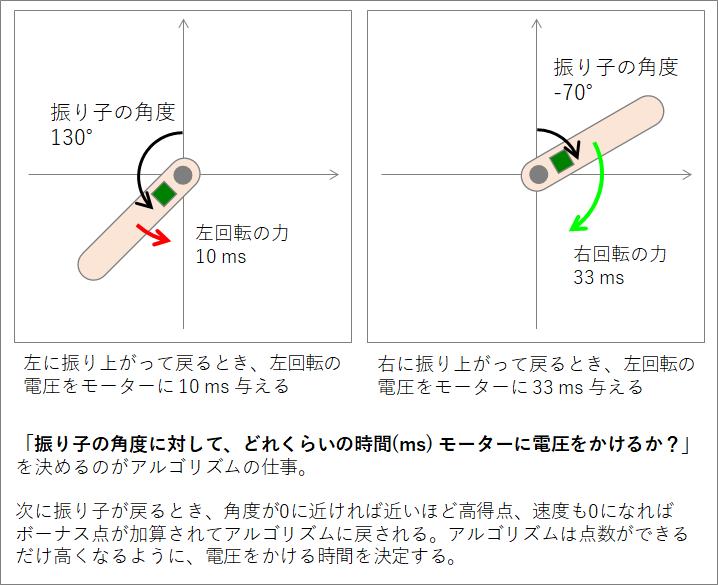
具体的な得点(報酬信号という)は、振り子が到達した角度を[math]\theta[/math] (randian) としたとき、
[math]
reward = – \theta^2
[/math]
とした。もし、[math]\theta[/math] の変化が0で、±5°の範囲に収まった場合には、ボーナス5点を加えて、
[math]
reward = – \theta^2 + 5
[/math]
とし、振り子を強制的に下にしてから再開した(ターミナル状態)。